本页目录
论文速记:深度学习
研究
【NeRF】NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (2020)
文章的主题 / 文章要解决什么问题?
使用稀疏输入2D图片集实现场景的3D视图合成。
文章的核心方法 / 具体是如何做的?
从()到()。
做了什么实验,效果怎么样?
测试数据集是Diffuse Synthetic 360、Realistic Synthetic 360和Real Forward-Facing。
研究的创新点
将输入坐标位置编码,帮助MLP表示高频函数;分层采样
有什么局限或可以改进的地方?
有效地优化和渲染神经辐射场;可解释性
更多笔记
神经辐射场用于从2D的图片重建3D的场景。
文中出现的三个指标PSNR、SSIM、LPIPS:
峰值信噪比(Peak Signal to Noise Ratio, PSNR):用于衡量图像恢复的质量,数值越高表示图像质量越好。接近50 dB代表误差非常小,大于30 dB人眼难察觉差异。
结构相似性(Structural Similarity Index Measure, SSIM):用于衡量图像的结构相似性,得分通常在0~1之间,数值越高表示图像结构越相似。相较于PSNR在图像质量的衡量上更能符合人眼对图像质量的判断。
基于学习的感知图像质量评价(Learned Perceptual Image Patch Similarity, LPIPS):测量从预训练网络中提取的两个图像的特征之间的相似性,得分通常在0~1之间,数值越低表示感知质量越高。
【Instant NGP】Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (2022)
文章的主题 / 文章要解决什么问题?
主要用于解决NeRF在对全连接神经网络进行参数化时的效率问题。
研究的创新点
提出了一种基于哈希搜索的编码方法。
更多笔记
Instant NGP与NeRF的异同
同样基于体渲染
不同于NeRF的MLP,Instant NGP使用稀疏的参数化的voxel grid作为场景表达
【3DGS】3D Gaussian Splatting for Real-Time Radiance Field Rendering (2023)
文章的主题 / 文章要解决什么问题?
实现实时辐射场渲染,同时保持高质量的视觉效果,并且保持较短的训练时间。
更多笔记
文章的相关工作部分
传统的场景重建与渲染:基于光场的,密集采样、非结构化捕获;运动恢复结构(Structure from Motion, SFM)用一组照片估计稀疏点云合成新视图;多视点立体视觉(Multi-View Stereo, MVS);
神经渲染和辐射场:用CNN估计混合权重,用于纹理空间;Soft3D提出Volumetric representations;NeRF提出重要性采样和位置编码来提高质量,但使用了大型多层感知器,对速度有负面影响。
稀疏重建和稠密重建
稀疏重建主要用于定位,得到每张图片的相机参数,提取特征点,例如SFM;稠密重建是假设相机参数已知的情况下,从不同视角的图像中找到匹配的对应点,对整个图像或图像中绝大部分像素进行重建。
【NeRF RPN】NeRF-RPN: A general framework for object detection in NeRFs (2022)
文章的主题 / 文章要解决什么问题?
在NeRF中直接进行3D物体检测。
文章的核心方法 / 具体是如何做的?
第一部分:特征提取器
从NeRF采样的辐射度和密度网格作为输入,生成特征金字塔作为输出。
第二部分:RPN头
对特征金字塔进行操作并生成对象建议。
研究的创新点
第一次将RPN引入NeRF以进行3D物体检测和相关任务;
利用Hypersim和3D-FRONT数据集构建了第一个用于3D目标检测的NeRF数据集。
【Instance NeRF】Instance Neural Radiance Field (2023)
文章的主题 / 文章要解决什么问题?
输入一个以多视图RGB图像预训练的NeRF,学习给定场景的3D实例分割。
文章的主要贡献:
第一个在NeRF中进行3D实例分割的尝试之一,而没有使用真实分割标签作为输入;
提出Neural Instance Field的结构和训练方法,可以产生多视图一致的2D分割和连续的3D分割;
对合成室内NeRF数据集进行实验和消融研究。
文章的核心方法 / 具体是如何做的?
Instance NeRF有两个组件:预训练的NeRF模型、和文中提出的Instance Field。
Instance Field的训练过程如下:
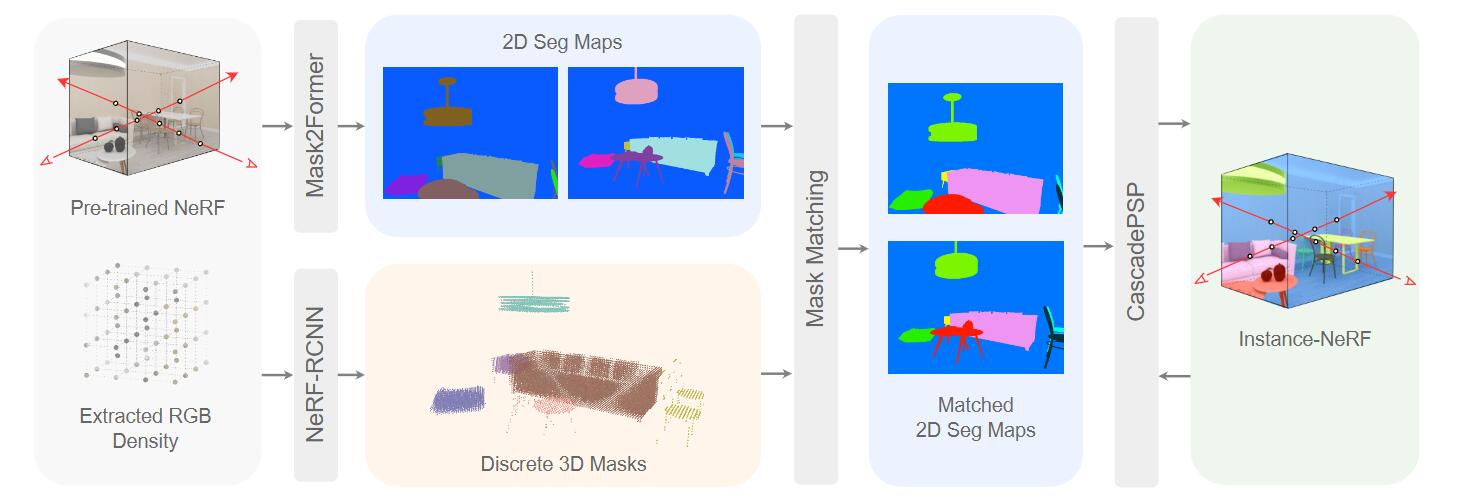
NeRF-RCNN用预训练的NeRF提取的辐射场和密度场,为每个检测到的对象输出3D掩码;Mask2Former生成从NeRF渲染的图像的二维全景分割图(跨视图的实例标签并不一定一致)。然后按照相机位置,投影3D掩码去匹配不同视图中的相同实例,去产生多视图一致的2D分割图。CascadePSP用于细化2D mask。
更多笔记
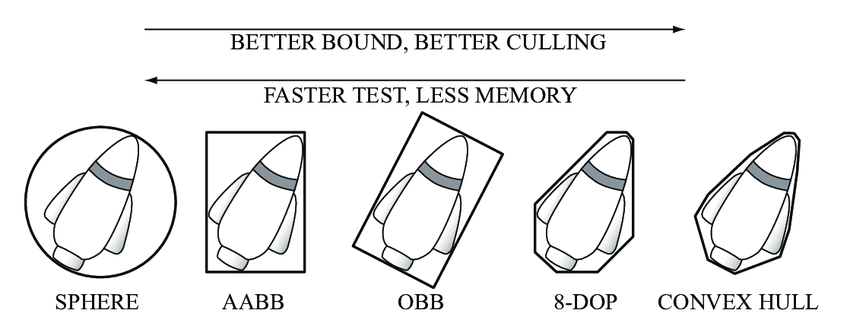
包围体:AABB和OBB
AABB:轴对齐包围盒(Axis-Aligned Bounding Box)
OBB:有向包围盒(Oriented Bounding Box)
下图展示了更多种类的包围体:
【CascadePSP】CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement (2020)
文章的主题 / 文章要解决什么问题?
提出一种不使用高分辨率训练数据,解决高分辨率分割问题的方法。右图是改进后的结果:

【SAGA】Segment Any 3D Gaussians (2023)
文章的主题 / 文章要解决什么问题?
交互式3D分割(promptable segmentation)。
学习
【R-CNN】Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation (2014)
文章的主题 / 文章要解决什么问题?
提出R-CNN(Regions with CNN features)提高目标检测性能。
文章的核心方法 / 具体是如何做的?
区域提议(Region Proposals):使用selective search生成候选。
做了什么实验,效果怎么样?
在PASCAL VOC 2012取得mAP 53.3%,在ILSVRC 2013竞赛数据集取得mAP 31.4%。
更多笔记
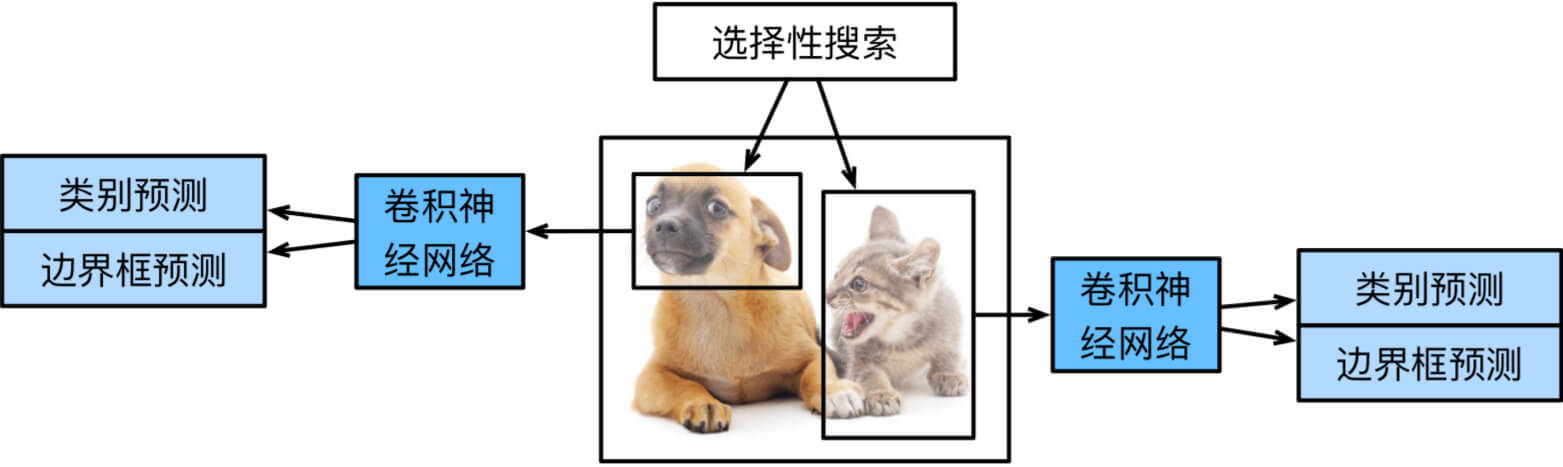
R-CNN
R-CNN使用启发式搜索算法selective search(之前人们通常也是这样做的)来选择锚框
用预训练的模型,对每一个锚框抽取特征
训练一个SVM来对类别分类
训练一个线性回归模型来预测边缘框
R-CNN的速度很慢,因为可能从一张图像中选出上千个提议区域,这需要上千次的卷积神经网络的前向传播来执行目标检测。这种庞大的计算量使得R-CNN在现实世界中难以被广泛应用。
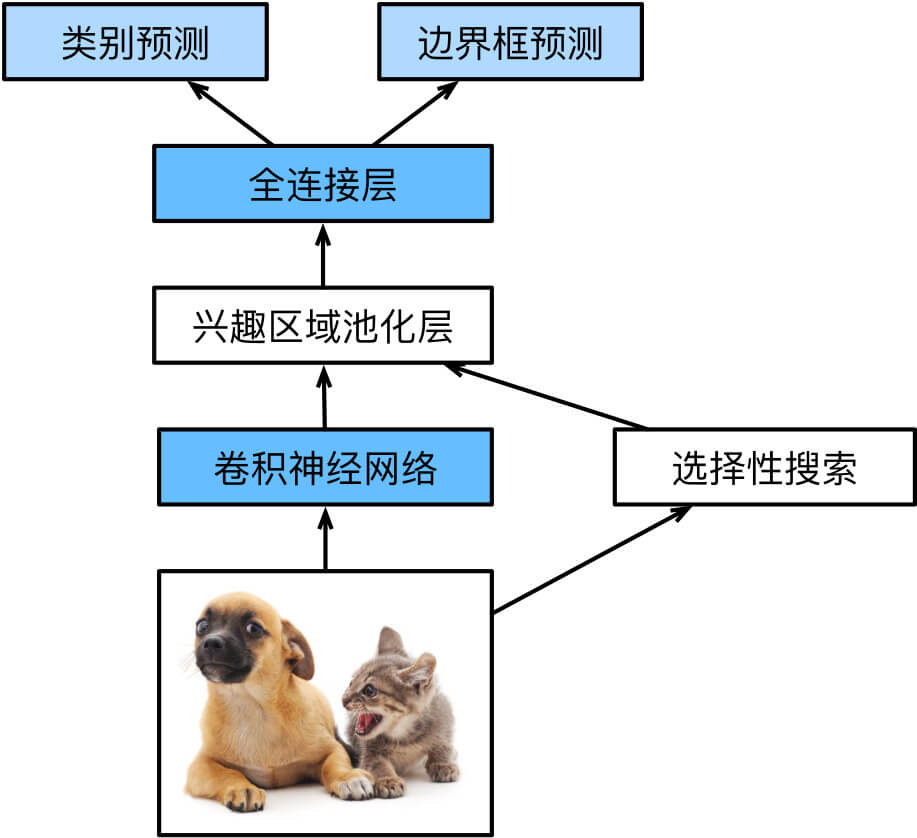
Fast R-CNN
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。Fast R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播,并且引入兴趣区域池化(ROI Pooling),将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征。
兴趣区域池化层可以给出固定大小的输出:把给定的锚框均匀分割成块,输出每块里的最大值,这样无论锚框多大,总是输出个值。
Fast R-CNN先对图片用CNN抽取特征,然后将selective search给出的原图上的提议区域映射到CNN特征图上,再经过ROI Pooling就可以得到维度对齐的特征。
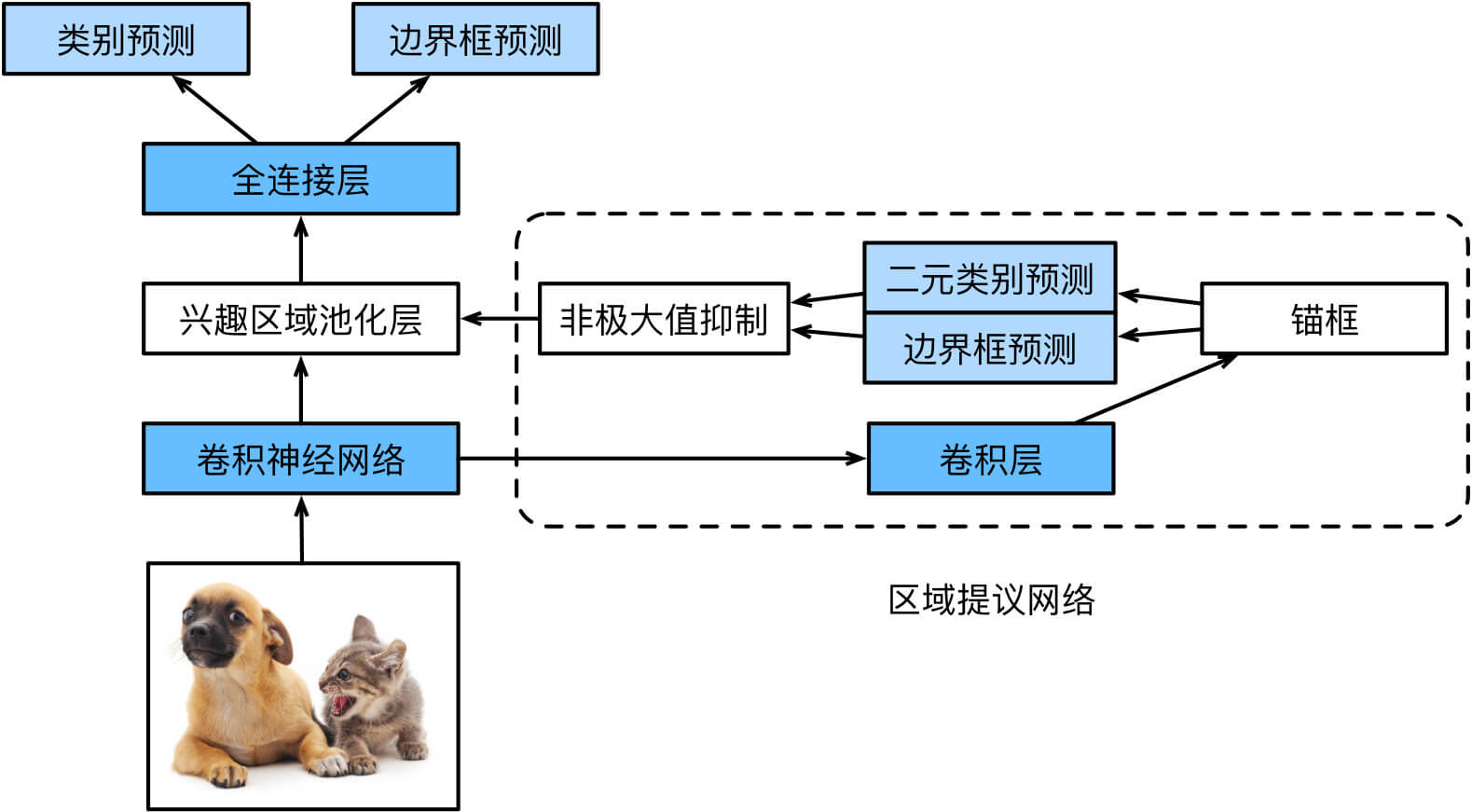
Faster R-CNN
与Fast R-CNN相比,Faster R-CNN将生成提议区域的方法从selective search改为了区域提议网络(Region Proposal Network, RPN),模型的其余部分保持不变。区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。换句话说,Faster R-CNN的目标函数不仅包括目标检测中的类别和边界框预测,还包括区域提议网络中锚框的二元类别和边界框预测。作为端到端训练的结果,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少了从数据中学习的提议区域的数量的情况下,仍保持目标检测的精度。
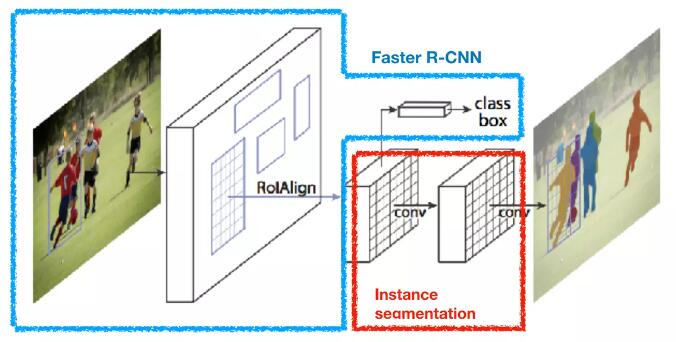
【Mask R-CNN】Mask R-CNN (2017)
文章的主题 / 文章要解决什么问题?
目标检测&实例分割
文章的核心方法 / 具体是如何做的?
基于Faster R-CNN,添加一个对每个ROI预测分割mask的分支。这个分支可以与分类和边界框预测分支并行。
做了什么实验,效果怎么样?
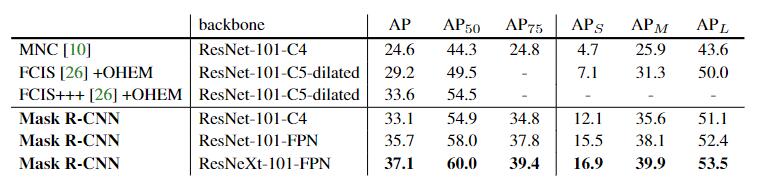
在COCO数据集上表现优异,超过了2015和2016年COCO分割任务的冠军。
研究的创新点
ROI Pooling中发生了两次浮点数取整,第一次是将锚框均匀分割成块时,第二次是把提议区域映射回CNN特征图时。
分割任务的精细程度更高,因此文章提出了ROI Align,使用双线性插值来保留特征图上的空间信息。
更多笔记
语义分割与实例分割
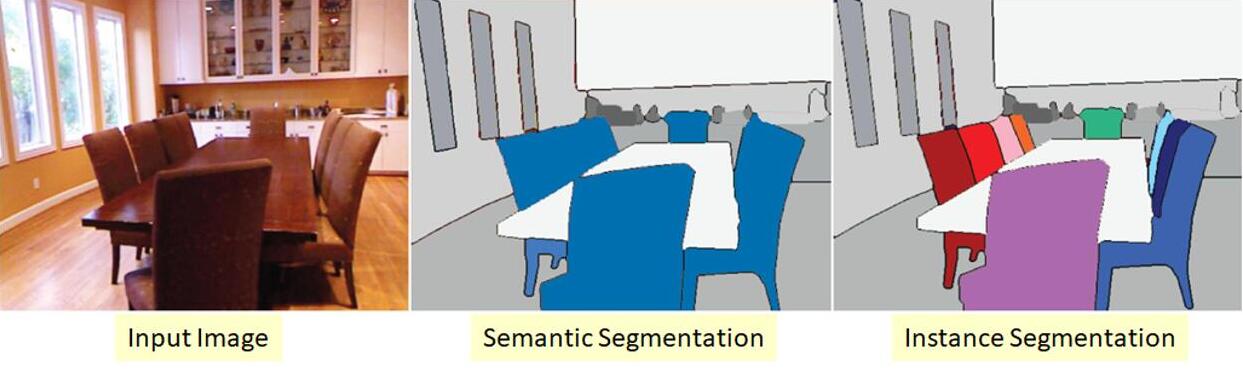
语义分割(semantic segmentation):为每一个像素分配一个类别,但不区分同一类别之间的对象。
实例分割(instance segmentation):会区分属于同一类别的不同实例。
【FCN】Fully Convolutional Networks for Semantic Segmentation (2015)
文章的主题 / 文章要解决什么问题?
使用全卷积网络进行语义分割。
文章的核心方法 / 具体是如何做的?
是将现有的分类网络(AlexNet、VGG Net、GoogLeNet)改造为全卷积网络,以便在语义分割任务上进行端到端(输入图像,输出分割掩码)的训练。
改造的方式是将最后的全连接层替换成卷积层。
更多笔记
转置卷积
卷积通常不会增大输入的高宽,而是保持不变或降低。由于语义分割任务需要像素级别的输出,转置卷积被用来增大输入的高宽。
图片转载自动手学深度学习 - 转置卷积
FCN中的转置卷积
例如对于ImageNet的图片输入,大小通常为(RGB通道);经过卷积后缩小宽高缩小32倍,通道增加到512,变成的特征图。此时FCN会先通过一个1x1conv进行通道降维,然后通过转置卷积将特征图的高度和宽度增加32倍,输出通道数等于类别数,相当于储存了对每一类的预测结果。
【GhostNet】GhostNet: More Features from Cheap Operations (2020)
文章的主题 / 文章要解决什么问题?
在嵌入式设备上部署CNN通常由于内存和计算资源受限而困难,GhostNet提出了Ghost模块,用低成本的操作生成更多特征图,可以作为一种轻量化的深度卷积模型架构
文章的核心方法 / 具体是如何做的?
特征图的各层之间有很多是相似的(冗余信息),论文希望能通过更低成本的计算量去获取它们。
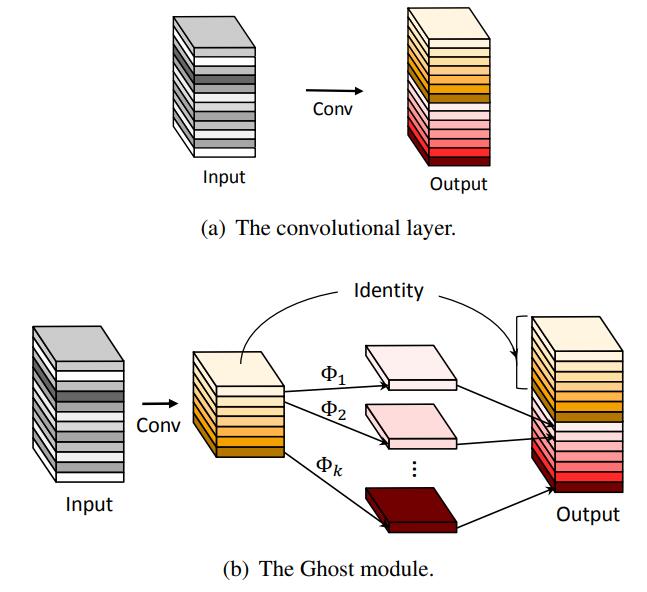
对于某个特征层,只用较少卷积操作生成部分真实的特征层(固有特征图),剩余的特征层通过对固有特征图的每个通道线性变换生成,最后将这些特征层拼接在一起。