本页目录
【程序分析】南京大学软件分析Lab3(死代码消除)思路
NJU程序分析死代码检测的Lab关注以下两种类型的死代码:
1.
不可达代码:控制流不可达(比如return之后的语句)和分支不可达(比如if(false))
2.
无用赋值:赋值语句的左值不在活跃变量集合中(并且等号右边的表达式没有副作用)
不可达代码涉及到对CFG图结构的分析,而无用赋值可以逐条语句进行检测,因此考虑先完成对不可达代码的检测。
从程序入口点开始,对CFG进行一次BFS,标记到达的节点(语句),即可排除掉控制流不可达的语句;对于分支不可达的语句,考虑在遍历的过程中选择他们的出边,就像把那些不可达的分支“剪掉”。比如对于这个例子(作业文档上的例子):
Java
int unreachableSwitchBranch() {
int x = 2, y;
switch (x) {
case 1: y = 100; break; // unreachable branch
case 2: y = 200;
case 3: y = 300; break; // fall through
default: y = 666; // unreachable branch
}
return y;
}
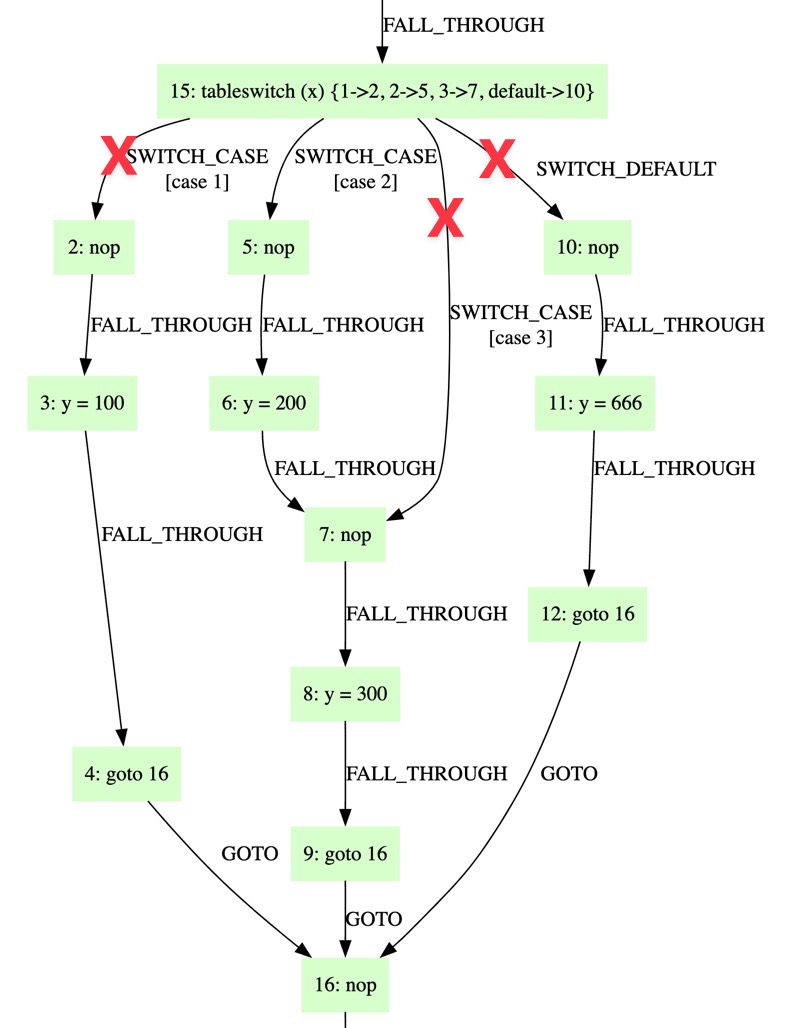
生成的CFG为:

对于switch语句,x为常量2,如果我们在遍历CFG的时候忽略其余的边,就等价于只剩一条从15->5->6->7->8->9->16的通路,其他分支上的(即使是不与节点15直接相连的)节点也自然不会被遍历到了。同时也不需要特殊考虑switch语句的fall through问题(语句y=200后没有break因此语句y=300也是可达的)。
代码侧面,实现getIfStmtReachableSuccs和getSwitchStmtReachableSuccs两个方法:
Java
// 获取if语句的“可达后继”
Set<Stmt> getIfStmtReachableSuccs(If ifStmt, CFG<Stmt> cfg, DataflowResult<Stmt, CPFact> constants) {
ConditionExp condition = ifStmt.getCondition();
Var op1 = condition.getOperand1(), op2 = condition.getOperand2();
Value v1 = constants.getInFact(ifStmt).get(op1), v2 = constants.getInFact(ifStmt).get(op2);
if (v1.isConstant() && v2.isConstant()) {
int c1 = v1.getConstant(), c2 = v2.getConstant(); // 条件表达式的两个操作数的(常量)值
boolean isTrue = switch (condition.getOperator()) {
case EQ -> c1 == c2;
case NE -> c1 != c2;
case LT -> c1 < c2;
case GT -> c1 > c2;
case LE -> c1 <= c2;
case GE -> c1 >= c2;
};
for (Edge<Stmt> edge : cfg.getOutEdgesOf(ifStmt)) {
// 条件值为常量true/false,只保留对应分支的后继
if (isTrue && edge.getKind() == Edge.Kind.IF_TRUE) {
return Set.of(edge.getTarget());
}
if (!isTrue && edge.getKind() == Edge.Kind.IF_FALSE) {
return Set.of(edge.getTarget());
}
}
}
// 条件值不是常量,保留所有后继
return cfg.getSuccsOf(ifStmt);
}
Java
// 获取switch语句的“可达后继”
Set<Stmt> getSwitchStmtReachableSuccs(SwitchStmt switchStmt, CFG<Stmt> cfg, DataflowResult<Stmt, CPFact> constants) {
Var condVar = switchStmt.getVar();
Value v = constants.getInFact(switchStmt).get(condVar);
if (v.isConstant()) {
int c = v.getConstant(); // switch语句的条件(常量)值
for (Edge<Stmt> edge : cfg.getOutEdgesOf(switchStmt)) {
if (edge.getKind() == Edge.Kind.SWITCH_CASE) {
int cv = edge.getCaseValue(); // case标签的值
// 有一个case标签的值等于条件值,只保留对应分支的后继
if (c == cv) {
return Set.of(edge.getTarget());
}
}
}
// 条件值为常量,但没有case标签的值等于条件值,只保留default分支的后继
return Set.of(switchStmt.getDefaultTarget());
}
// 条件值不是常量,保留所有后继
return cfg.getSuccsOf(switchStmt);
}
这两个方法会返回条件/分支语句“可达”的后继节点,如果条件值不是常量则等价于cfg.getSuccsOf(stmt)(返回所有后继),否则只会返回命中条件的那个后继节点。
在BFS时,对于条件/分支语句,改为用这两个方法获取语句的后继节点,即可完成对不可达代码的判断;BFS完成之后再逐语句进行无用赋值的检测即可,代码如下:
Java
@Override
public Set<Stmt> analyze(IR ir) {
// obtain CFG
CFG<Stmt> cfg = ir.getResult(CFGBuilder.ID);
// obtain result of constant propagation
DataflowResult<Stmt, CPFact> constants = ir.getResult(ConstantPropagation.ID);
// obtain result of live variable analysis
DataflowResult<Stmt, SetFact<Var>> liveVars = ir.getResult(LiveVariableAnalysis.ID);
// keep statements (dead code) sorted in the resulting set
Set<Stmt> deadCode = new TreeSet<>(Comparator.comparing(Stmt::getIndex));
// TODO - finish me
// Your task is to recognize dead code in ir and add it to deadCode
// 1.不可达代码
Queue<Stmt> queue = new LinkedList<>();
Set<Stmt> visited = new HashSet<>();
Stmt entry = cfg.getEntry();
queue.add(entry); // BFS遍历图
while (!queue.isEmpty()) {
Stmt stmt = queue.poll();
visited.add(stmt);
Set<Stmt> reachableSuccs;
if (stmt instanceof If ifStmt) {
// if语句的“可达后继”
reachableSuccs = getIfStmtReachableSuccs(ifStmt, cfg, constants);
} else if (stmt instanceof SwitchStmt switchStmt) {
// switch语句的“可达后继”
reachableSuccs = getSwitchStmtReachableSuccs(switchStmt, cfg, constants);
} else {
reachableSuccs = cfg.getSuccsOf(stmt);
}
for (Stmt succ : reachableSuccs) {
if (!visited.contains(succ)) {
queue.add(succ);
}
}
}
// 遍历一遍之后,可以找到所有控制流不可达和分支不可达的语句
for (Stmt stmt : cfg) {
if (cfg.isExit(stmt)) continue;
if (!visited.contains(stmt)) {
deadCode.add(stmt);
}
}
// 2.无用赋值
for (Stmt stmt : cfg) {
/*
见作业文档:
AssignStmt和Invoke都是DefinitionStmt的子类,但方法调用可能含有很多副作用,
因此对于像 x = m(); 这样的语句,即使x之后再也不会被用到(x是无用变量),
这条语句也不会被认为是无用赋值。因此,本次作业中所有可能的无用赋值都只可能是AssignStmt的实例。
*/
if (stmt instanceof AssignStmt assignStmt) {
LValue lval = assignStmt.getLValue();
RValue rval = assignStmt.getRValue();
if (lval instanceof Var && !liveVars.getOutFact(stmt).contains((Var) lval) && hasNoSideEffect(rval)) {
deadCode.add(stmt);
}
}
}
return deadCode;
}