本页目录
BlueHens CTF 2024 Writeup

Web
lists of JSONs
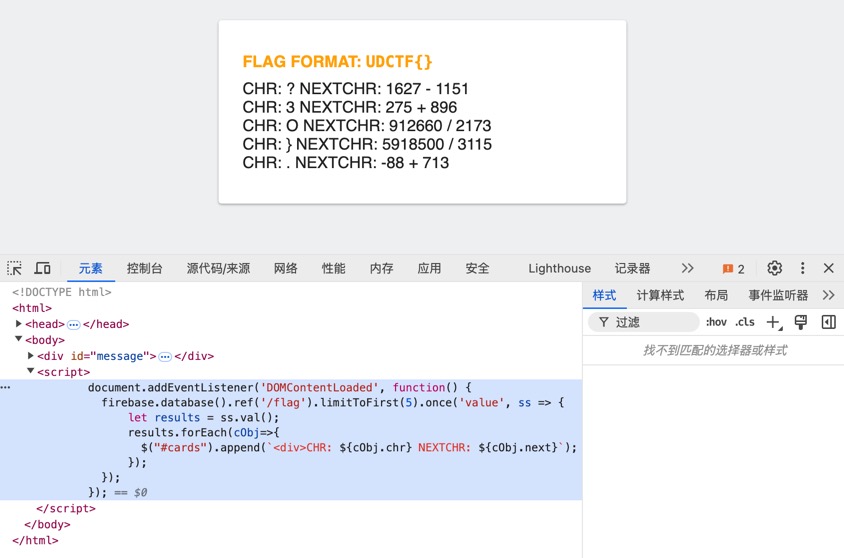
limitToFirst(5)不够,在控制台贴上:
(function () {
let cardsElement = document.getElementById("cards");
cardsElement.innerHTML = "";
firebase
.database()
.ref("/flag")
.limitToFirst(12000)
.once("value", (ss) => {
let results = ss.val();
results.forEach((cObj) => {
$("#cards").append(`<div>CHR: ${cObj.chr} NEXTCHR: ${cObj.next}`);
});
});
})();
实际数据的条数只有1900多一点;大概就是一个类似链表的结构,然后用Python去遍历输出:
hints = """CHR: ? NEXTCHR: 1627 - 1151
CHR: 3 NEXTCHR: 275 + 896
CHR: O NEXTCHR: 912660 / 2173
CHR: } NEXTCHR: 5918500 / 3115
CHR: \ NEXTCHR: -1963 + 3668
...
CHR: ! NEXTCHR: (191 * 1) + 46
CHR: E NEXTCHR: (2074 * 0) + 415
CHR: | NEXTCHR: (3310 * 0) + 1422
CHR: \ NEXTCHR: -1963 + 3668
CHR: o NEXTCHR: 3775 - 3429
CHR: END NEXTCHR: You got the flag"""
lines = hints.split("\n")
data = []
for line in lines:
s1, s2 = line.split(" NEXTCHR: ")
chr = s1[5:]
if s2 == "exit()" or s2 == "You got the flag":
data.append((chr, -1))
continue
nextpos = int(eval(s2))
data.append((chr, nextpos))
pos = 0
while True:
chr, nextpos = data[pos]
if chr == "END":
break
print(chr, end="")
pos = nextpos
表达式用eval处理很方便,但是题目中混入了exit(),要单独筛一下。输出为:
?tCUzc-Hj,xMUjas&TF{JS0N_1n_tr33}o`JM0FYNNonogram Pt. 2: Disgraced
正常玩一遍Nonogram,通过后显示的是乱码:

全局搜索找一下设置这个div内容的函数:
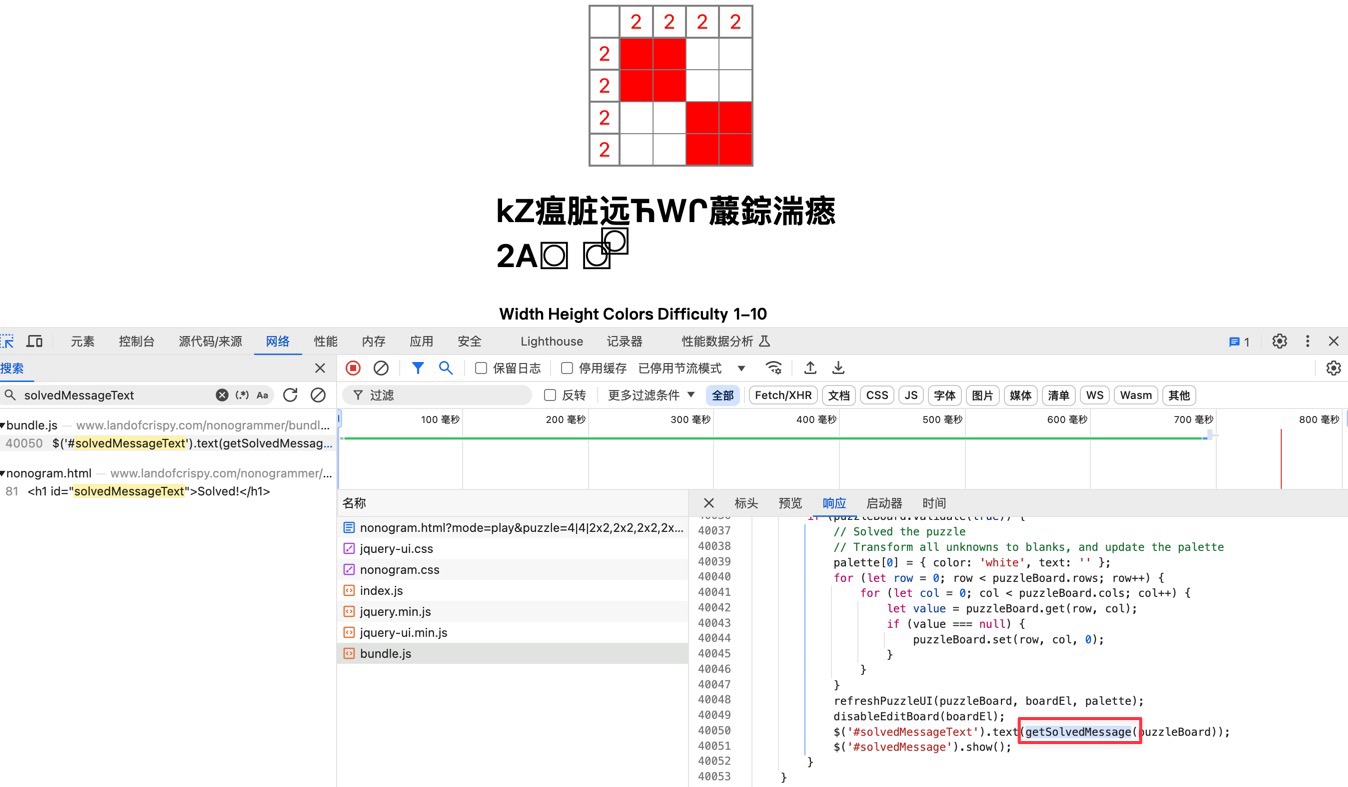
打断点调试一下,看到解密用的key就是当前Nonogram面板上的状态;而密文来自于URL参数,是一个定值。
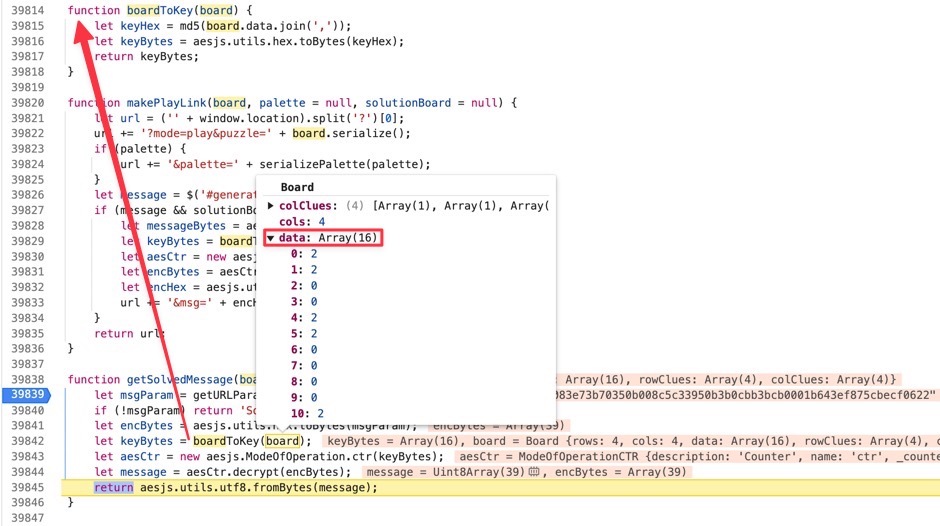
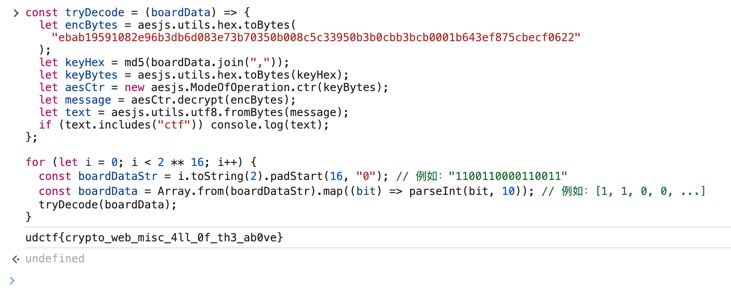
尝试了两种满足条件的解法发现解码的消息都是乱码,因此直接想爆破了;理论上每一个小块可以是0/1/2(不填/黑/红),但是刚试二进制的组合时就成功了。代码如下,直接贴到控制台运行即可。注意要在调试没结束的状态下运行,不然有一些局部变量未定义。
const tryDecode = (boardData) => {
let encBytes = aesjs.utils.hex.toBytes(
"ebab19591082e96b3db6d083e73b70350b008c5c33950b3b0cbb3bcb0001b643ef875cbecf0622"
);
let keyHex = md5(boardData.join(","));
let keyBytes = aesjs.utils.hex.toBytes(keyHex);
let aesCtr = new aesjs.ModeOfOperation.ctr(keyBytes);
let message = aesCtr.decrypt(encBytes);
let text = aesjs.utils.utf8.fromBytes(message);
if (text.includes("ctf")) console.log(text);
};
for (let i = 0; i < 2 ** 16; i++) {
const boardDataStr = i.toString(2).padStart(16, "0"); // 例如:"1100110000110011"
const boardData = Array.from(boardDataStr).map((bit) => parseInt(bit, 10)); // 例如:[1, 1, 0, 0, ...]
tryDecode(boardData);
}
Reversing
Bainrot.c
肉眼反混淆,纯粹的精神污染,感受下源码:
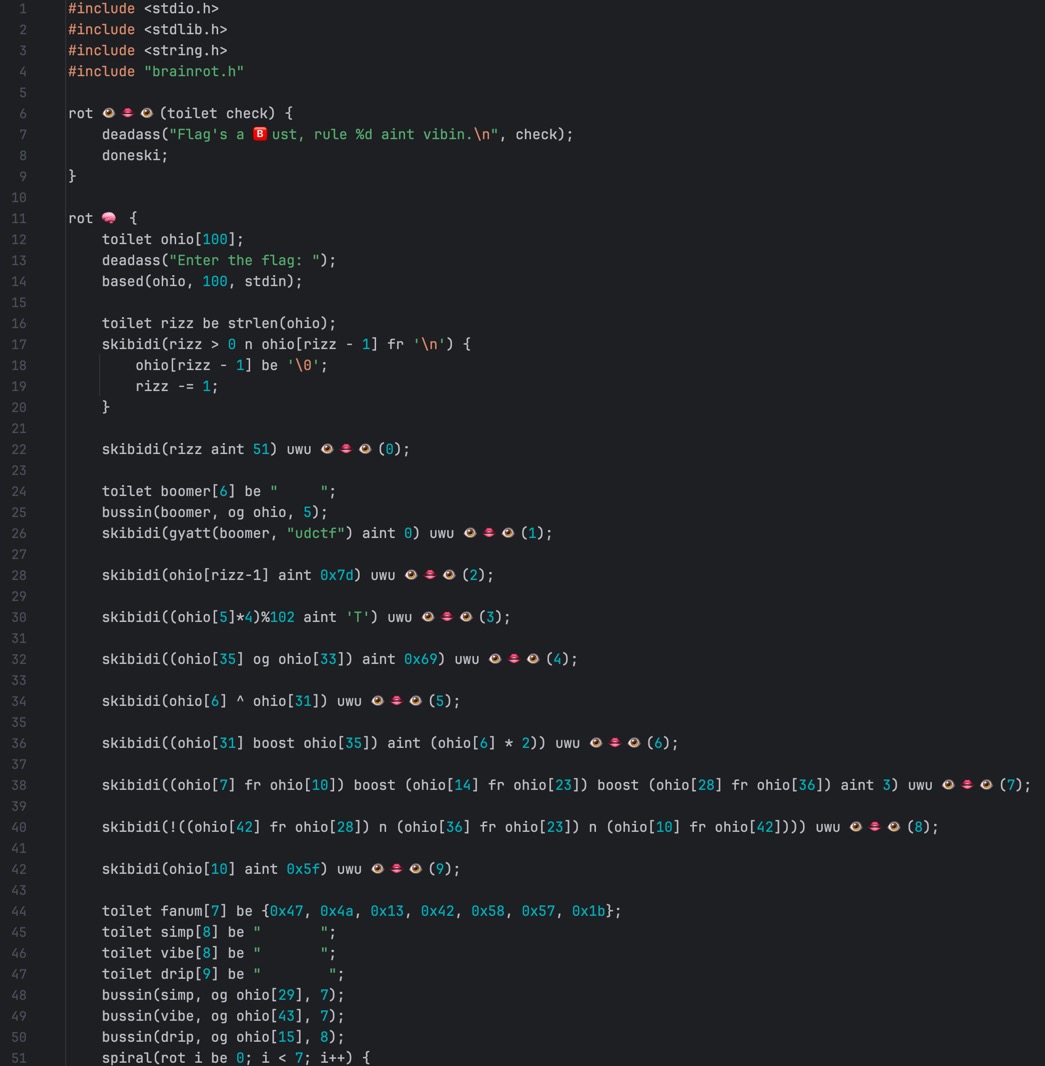
用很多俚语/梗代替了正常的C关键字,但是语法结构没有破坏,可以一点一点猜出来,边猜边全局替换,就越看越懂了。题目的大意就是给flag设置了一系列的验证规则,需要全部通过。解题的过程就是根据规则确定flag的中间位。第25位没有线索,是根据源码中的ohio推测出来的。
flag = [" "] * 51
flag[0] = 'u'
flag[1] = 'd'
flag[2] = 'c'
flag[3] = 't'
flag[4] = 'f'
flag[5] = '{'
flag[10] = chr(0x5f) # _
flag[-1] = chr(0x7d) # }
l1 = [0x47, 0x4a, 0x13, 0x42, 0x58, 0x57, 0x1b]
s1 = "r!zz13r"
for i in range(7):
flag[29 + i] = chr(l1[i] ^ ord(s1[i]))
s2 = "5ki8idi"
for i in range(7):
flag[43 + i] = chr(l1[i] ^ ord(s2[i]))
l2 = [0x40, 0x05, 0x5c, 0x48, 0x59, 0x0f, 0x5a, 0x5b, 0x00]
for i in range(8):
flag[15 + i] = chr(l2[i] ^ ord(s2[i % 7]))
l3 = [0x62, 0x6e, 0x60, 0x75, 0x69, 0x34, 0x00]
for i in range(6):
flag[8 + i] = chr(l3[i] - 1)
l4 = [0x05, 0x17, 0x01, 0x01, 0x1d, 0x00]
for i in range(5):
flag[37 + i] = chr(l3[i] ^ l4[i])
flag[6] = flag[31]
flag[26] = flag[44]
flag[24] = "0"
flag[27] = "0"
flag[7] = flag[10]
flag[42] = flag[10]
flag[28] = flag[42]
flag[36] = flag[28]
flag[23] = flag[36]
flag[14] = flag[23]
flag[25] = "h" # guess from "ohio"
print("".join(flag))
udctf{i_am_th3_un5p0k3n_0h!0_5ki8idi_gyatt_r!zz13r}XOR School系列
应该是这次比赛的特色吧,感觉偏向密码学一点。一共解了三题,后两题思路都非常相似(靠猜)。
XS1
# In [15]: (flag*32)[::17][:32]
# Out[15]: 'u_cnfrj_sr_b_34}yd1tt{0upt04lbmb'
out = "u_cnfrj_sr_b_34}yd1tt{0upt04lbmb"
flag = [" "] * 100
for i in range(len(out)):
flag[i] = out[(i * 17) % 32]
print("".join(flag))
udctf{just_4_b4by_1ntr0_pr0bl3m}XS3
我做的时候大致的历程是三步:首先,本题是同一个key加密多个明文,可以利用ASCII字符之间异或小于64,而ASCII字符异或空格大于64这个特性,第一阶段先过出可能被泄露的位:
ciphers = [
'43794c9c8faa2cff24edc8afe507a13f62837c7e166f428cab5aff893225ff19104bc8754c1c09',
'5d315e8786e62cf763e9d4afe80ca13b649a717e11615986b642f3952f76b71b0342c4',
'46785a8bcae62aeb60a5deeef107a1256ed7792752695886ff50f5886171ff1717',
'5d315e819fe621b966e08dfae906e43a78837b31162e5e8cff46e8953275f20a0d5ad23d4712144c',
'557f4dce9ee220b967e4dfffe616e9216a9934291b7d5690bb45ba922e6afc',
'55315a868fef35f16beac6afe810a1206a81717e1e6b5690b152ba953462ff0c424acd6e0307055a81b93590c1fe',
'557d489dcafd2df870a5cfe0e816f268628334291b7a5fc2aa58f99f3276f616160fc27c5116',
'557f4dce8bee21fc24f1c5eaa712ee3f6e853431142e448db216fb9e2b70e5110c48816b46011e5a',
'407e099783ef29fd24edc4fca704f33d6283343f1c6a178ab645ba962464f1581147c0714f530350d5f53690dee6',
'40785ace93e530b970edccfba711e0312b9e607e1c6143c2b616e3953425f317425bc9780317085ac5a6',
]
# target:
target = "41754a9a8cf13da976dac4e1d810b1253f994b6f47514387b106e8a57175a40a0370d22c4d14084d9ea8"
def cipher_to_byte_list(cipher):
return [int(cipher[i:i + 2], 16) for i in range(0, len(cipher), 2)]
ciphers = [cipher_to_byte_list(c) for c in ciphers]
target = cipher_to_byte_list(target)
stats = [[] for _ in range(len(target))]
def leak(cipher):
for i in range(min(len(target), len(cipher))):
if target[i] ^ cipher[i] >= 64:
stats[i].append(cipher[i] ^ target[i] ^ ord(' '))
for cipher in ciphers:
leak(cipher)
def mode(ls):
if ls:
return max(set(ls), key=ls.count)
else:
return 0
message = ""
for stats_ch in stats:
if len(stats_ch) > 4:
message += "."
else:
m = mode(stats_ch)
if len(stats_ch) == 1 or stats_ch.count(m) > 1:
message += chr(m)
else:
ch = "."
for c in stats_ch:
if 65 <= c <= 90 or 97 <= c <= 122:
ch = chr(c)
message += ch
print(message)
.dctf{..r_in_..m.n_.._ten.r..p.ra_s.ng..k}剩下的部分中.可能是这一位上刚好没有任何密文的对应位置是空格,或者这一位是ASCII码值小于64的字符(比如数字)等等。已经知道flag前缀是udctf,并且题目说了密文是诗歌中的句子,因此第二阶段可以开始根据某句话的语义推测出一个没拼写完的单词,只要恢复任意一条密文的下一个位置,就可以恢复key的一位。
理论上这个过程可以一直重复下去,但其实猜到一定数量就可以Google一下了,找到原文:https://milton.host.dartmouth.edu/reading_room/comus/text.shtml
第三阶段,找到其中一句(长度够的话)就可以恢复全部到密钥。最后的代码如下(整个脚本是一边推测一边完善的):
# ----- guess the rest -----
ciphers.append(cipher_to_byte_list(
"41754a9a8cf13da976dac4e1d810b1253f994b6f47514387b106e8a57175a40a0370d22c4d14084d9ea8" # target
# "d c t f { x 0 r _ i n _ r 0 m 4 n _ 1 5 _ t e n 0 r _ 0 p 3 r a _ s 1 n g e r ? } "
))
key = [
52, 17, 41, 238, 234, 138, 69, 153, 4, 133, 173, 143, 135, 98, 129, 72, 11, 247, 20, 94, 114, 14, 55,
226, 223
] # try byte by byte
# enough info to find the poem:
# https://milton.host.dartmouth.edu/reading_room/comus/text.shtml
c7 = "and adde the power of som adjuring verse"
for i in range(len(key), len(c7)):
key.append(ord(c7[i]) ^ ciphers[7][i])
key.append(161)
key.append(213)
for cipher in ciphers:
for i in range(min(len(key), len(cipher))):
print(chr(cipher[i] ^ key[i]), end="")
print()
udctf{x0r_in_r0m4n_15_ten0r_0p3ra_s1nger?}XS10
看到加密后的代码,推测还是用了相同的密钥对每一行对应位置做异或加密,因为观察前几列能发现有很多重复出现的组合。
这题我找到的突破口是高亮颜色:

PHP代码中注释的颜色是亮橙色,因此推测5a4b是//的加密,然后恢复出密钥的前两位;后面的猜测就跟XS3非常相似,例如看到ec出现了几次自然就会猜测后两位是ho,从而继续恢复密钥。编程语言猜起来比诗歌简单很多。
code = ("""5308174f590b0103555810
13110d171212061d7f
0d0b112b03150a01260844
5d
5100020007
5944
510f060d
5c44187e465b4953
5116060713171d53
4844
5243
4e6e4354465b0f1c2d5818
510d43
4844
45
4e44
510d43
5308174f46
061011180315
5d
5100020007
5c5f43
510d
5e4f4a541d7149537f5810527f47
5116060713171d53
5b5943
5100020007
2e
510d
28443d54
510f060d
2e
510d43
5044
061011180315
5d
510f060d
5c39587e465b4953227210527f47075607060b3110
000a13150510
5d
572c4956
59
5116060713171d
5c3f
44
285f6954460663797f58
510f060d46
4844
52110717121d121a2c2748422d38124640000a266f422d315e444b420843
4e6e695446
51070c10035b
4844
1d0d041c0a120e1b2b27561b3302
5d
2a3b253d2a3e362c
5944
01161611
5c5f695446
510b011213080a122b1d542d3c08115653
4844
0516061339090c03331953170004145f1f11183c5b
5d6e4354465b
524b451812401a033e16182901411247482e537616152b55185a15425c420f005d2746002f195e5438134e1c0054
596e4354465b0f06311b441b3009551b
5109020005130c00
5c441607035b41
510f060d
5c44187e465b49537f581052
51070c1a121e07077f
4844
5109020005130c00
2e
47
285f6954465b49537f5810
510b011213080a122b1d542d3c081b47161d0d7f
4844
0d0b112b03150a01260844
5d
51070c1a121e0707
5944
510f060d
5c5f6954465b49537f5810003a1300411d53
52420f005d081912315f
5b
5109020005130c00
2e
44
284a
524204005d5c49
5b44
1d100e18150b0c1036195c1137060740
5d
510b011213080a122b1d542d3c081b47161d0d
5c444d54
52420f005d541a033e1616152b5c535f07481b2d16152b5517
4e6e4354465b145f555810527f
51070c1003714953
5c5f695446
5a4b4710091801073214104f7f09104453373612741d3c1b5d1151095d4d587e465b465c7b1c5f113713185f5e551e2b0b1e300f545c1b1e1a00065d5d714953
10070b1b46
510b011213080a122b1d542d3c081156
4e6e4354
5a4b13060f151d2c2d50451c2f0616585b513175125e7b0d5f105a542e553e5d5d71
4a4204005d71""")
def cipher_to_byte_list(cipher):
return [int(cipher[i:i + 2], 16) for i in range(0, len(cipher), 2)]
code = code.split("\n")
code = [cipher_to_byte_list(line) for line in code]
key = [117, 100, 99, 116, 102, 123, 105, 115, 95, 120, 48, 114, 95, 103, 117, 51, 115, 115, 121, 95, 48, 114, 95, 110,
48, 116, 63, 125, 117, 100]
for line in code:
if not len(line) >= len(key):
continue
for i in range(min(len(key), len(line))):
print(chr(line[i] ^ key[i]), end="")
if len(line) > len(key):
print(line[len(key):], end="")
print()
udctf{is_x0r_gu3ssy_0r_n0t?}