本页目录
论文阅读:zxcvbn: Low-Budget Password Strength Estimation (Security 2016)
相关链接:
1.Introduction
本文主要提出一个易于实现的密码强度检测器。研究者来自Dropbox。
2.Background and Related Work
LUDS
一种常见的密码强度估计方案:利用小写字母(Lowercase)、大写字母(Uppercase)、数字(Digit)和特殊字符(Symbol)的出现次数来评估密码强度,简写为LUDS,这种策略可以追溯到NIST(美国国家标准与技术研究院)的标准。作者认为这种估计方案从根本上就是无效的——Passw0rd因为有数字0,反而会比QJqUbPpA这样明显随机的密码拥有更高的分数;密码中常见的模式,如日期、键盘规律(比如qwerty)无法在分数中有体现。
NIST的标准(通常叫NIST熵)伪代码见下图:

前两条都是LUDS规则:根据密码长度和特殊字符加分;尽管第三条(是可选的)考虑了字典攻击,前面的例子Passw0rd(假设它没通过字典测试)依然会得到和QJqUbPpA(假设它通过了)一样的分数,这是令人困惑的。
密码猜测相关
本文使用的“黄金准则”(原文是gold standard,含义类似于Ground Truth,在后面的实验用于验证强度估计的准确性)是利用Ur等人提出的Password Guessability Service(论文在这里,后面简称PGS)得到的面对四种现代密码猜测攻击中,需要进行的最少限度的尝试。
本文将区分在线猜测(攻击者通过公共界面进行猜测)和离线猜测(拿到哈希值之后攻击者可以在自己的硬件上爆破)。
3.Evaluation Framework
对于一个旨在替代LUDS的方案,这一节讨论了各方面的评价标准。作者参考了两种LUDS方法:NIST熵和3class8(一种易于采用的要求,即密码包含至少3种类型的8个或更多字符)。
新的方案不应该比LUDS方案更难被采用。
新的方案只应该警告那些真正存在风险的用户。
新的方案应该直接以“猜测这个密码所需的尝试次数”作为标准。(因为这是安全社区对密码强度定义的共识)
在小数量级上要保证准确性。
在线攻击同样是一个重要威胁,能够在约几百次内猜测出的密码对于在线攻击显然是脆弱的,但NIST熵会严重高估这种密码的安全性。作者将作为在线攻击的阈值(认为需要猜测以上次的密码对于在线攻击相对安全),并希望新的方案能够在阈值之前保持较高的准确性。
新的方案应该可以选择不同的数据集大小,应该给予使用者自主权衡大小和准确性的权利。
4.Algorithm
形式化的表达:
表示一个模式,它可能是一个满足格式的日期、一段键盘上相邻的字符串等等:

对于一个给定的密码字符串,可以匹配到多种模式,并且这些模式会有重叠,例如密码lenovo1111可能提取到lenovo(token)、eno(reversed 'one')、1111(repeat)、1111(date of 2011/1/1)等模式。
如果一部分模式能够不重不漏地组成原始的密码字符串,这个模式序列就计作。代表模式的数量。
连乘项代表对于所有模式,最坏情况下猜测的总数;考虑了不同模式之间的组合顺序;代表攻击者事先不知道模式的长度时,从尝试到;是一个常数,反映对于单个模式需要猜测的次数,因此猜测总次数。
算法的流程
从密码中提取模式集合;
对于集合中每一个模式,估计猜测这个模式所需的次数m.guesses;
从中搜索(论文用动态规划做的)一个不重不漏组成密码的序列,使得前面提到的评估式最小。
(整体的思想就是,找到一个最容易猜出,也就是猜测次数最少的的模式,用这个模式所需的猜测次数来代表密码强度。)
局限
没有考虑模式之间的依赖性,例如常用的短语搭配;不会把错拼的单词匹配为模式;等长的不匹配区域逻辑上是等效的,尽管有些可能的组合比完全等长的随机字符更常见。
5.Experiments
首先理解实验结果的坐标图:
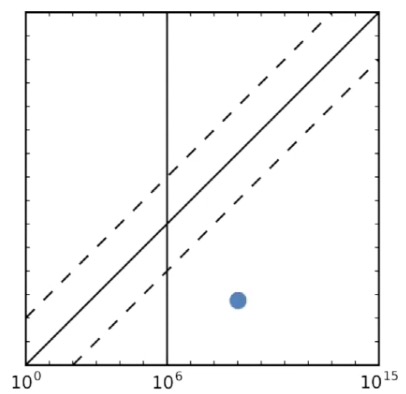
这是一个对数 - 对数坐标,轴是前面提到的黄金准则PGS,轴是估计;在处的竖线是在线攻击的阈值;越接近这条实线说明密码强度估计与PGS得到的结果越接近,虚线是一个大致不错的范围。
图中的蓝点所在位置,表示估计的强度低于密码真实的强度(假设PGS真实反映了密码强度),这是一个易用性问题(用户觉得:我的密码明明很强,为什么还是不合格?);相对的,如果落在上面的区域,就代表估计的强度高于密码真实的强度,那么这是一个安全性问题。
算法选择
在算法选择上对比了NIST熵、KeePass(另一个不基于LUDS的估计方案)和zxcvbn(本文提出的方案):
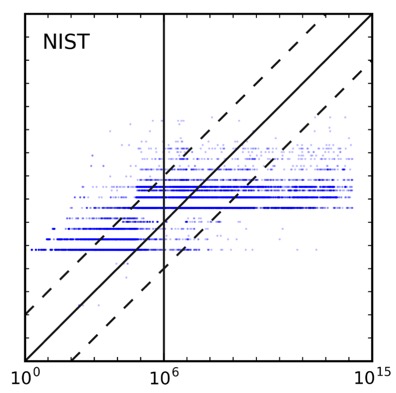
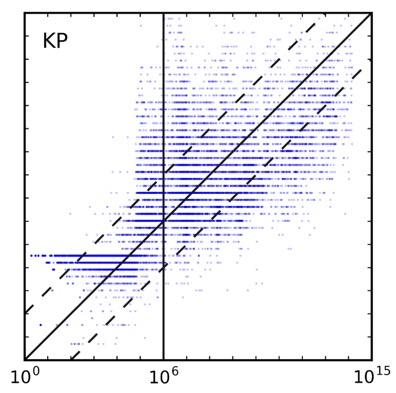
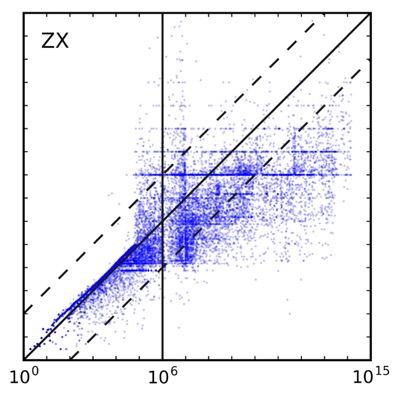
能看到zxcvbn确实在低数量级(在线攻击区间)有更高的准确性。
看到各图中都有很多水平的“条带”,一般来说LUDS方法对具体字符的不敏感的,比如hello、abcde、vdskj很可能具有相同的分数,此时大量的密码都对应了同一个估计分数,但是PGS指标可能相差较多,就形成了一条水平线;
本文提出的zxcvbn,在中高数量级也出现了条带状,这对应着bruteforce模式(没有其他模式匹配得上,只能暴力)。
其他
论文还做了关于数据集大小选择(100k/10k/1k token sets)或只考虑某一部分模式对结果的影响,以及运行性能分析,具体见论文原文。
6.Conclusion
zxcvbn易于在客户端使用,运行速度毫秒级,可以配置数据集大小,能够准确和保守地预测在线攻击范围内的密码强度。