本页目录
模型优化概述:量化、压缩、轻量化
模型量化技术
模型量化的主要思路是寻找一个映射函数,将高精度的值映射为低精度的值(降低位宽),且保证效果相似,以降低存储成本和计算需求。量化的对象通常是权重数据和激活数据。根据量化间距是否相等分为线性量化(均匀量化)和非线性量化(非均匀量化)。
线性量化
分类
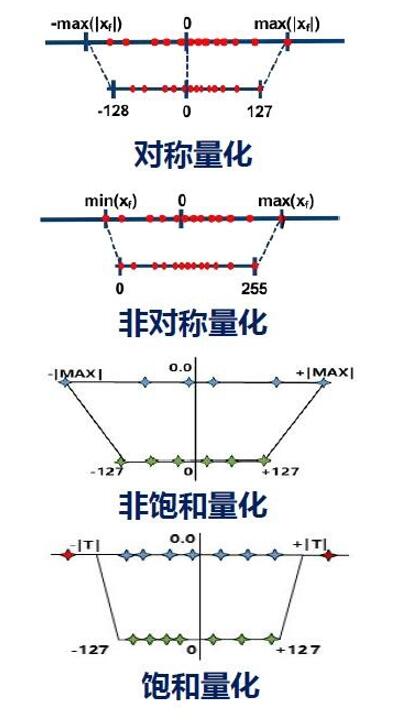
根据float32的零点是否映射到int的零点可以分为对称量化和非对称量化。
如果float32的绝对值最大映射为127,则称为非饱和量化;选择合适阈值映射为127,则称为饱和量化。权重常用非饱和量化,激活常用饱和量化。
浮点化定点
将float32化为8位动态定点数,需要指定小数位数,表示的数为。例如时,8位依次是符号位1位,整数位3位,小数位4位,数值范围为~,分辨率为。
应用时,同一层激活(或权重)小数位数相同,不同层激活(或权重)小数位数可以不同。
仿射映射量化
原数(实数)和量化表示(整数)的关系:
其中是量化步长,是零点(整数)。相应地,量化计算公式为:
参数、的确定公式为:
例如,希望将数据范围映射到8位整数(范围~),计算参数为:
非线性量化
权重和激活分布不均匀时,可以采用变间隔的量化以提高精度。常见的非线性量化包括:
对数量化(移位量化):量化值在以为底的对数域上均匀分布;此时乘法计算可以简化为移位。
学习量化(权重共享):对权重聚类分组,每组分配一个值,构建码本,组内权重映射到该值。
模型压缩技术
网络剪枝
给定一神经网络模型,去除该模型中对最终结果影响不大的参数,获得结构更为精简的模型,该过程被称为网络剪枝(Neural Network Pruning)。
非结构化剪枝
细粒度的剪枝,将不必要的权重归零;模型准确率损失更小,但部署时需要特殊的硬件和优化库支持其稀疏运算。
结构化剪枝
粗粒度的剪枝,直接丢弃整个神经元、卷积核整行、整列、整个通道甚至整个卷积核;模型准确率受影响更大,但能很好部署在SIMD或通用并行结构平台上。
基于SVD分解的模型压缩
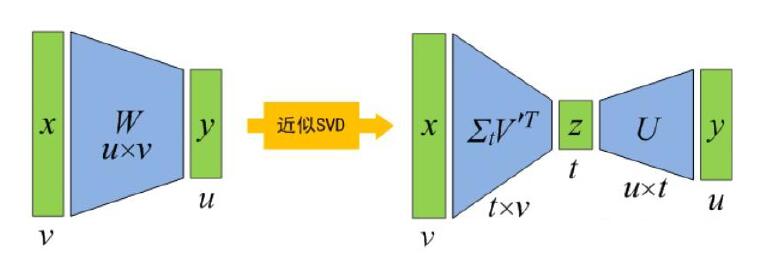
将做SVD近似,使用两个全连接层和代替:
取最大的前个奇异值,则计算量为。
模型输出压缩
观察到ReLU激活函数下,输出具有稀疏性(很多位置为0值),可以考虑如下压缩方案:
游程编码
硬件优化,跳过运算涉及的权重读取、跳过运算的时钟周期等
删减低值激活,牺牲一定准确性,进一步增加特征图稀疏程度
轻量化模型
基于不同卷积类型的轻量化网络
常规卷积
假设卷积核,输入通道,输出通道,常规卷积需要的参数量为。
分组卷积
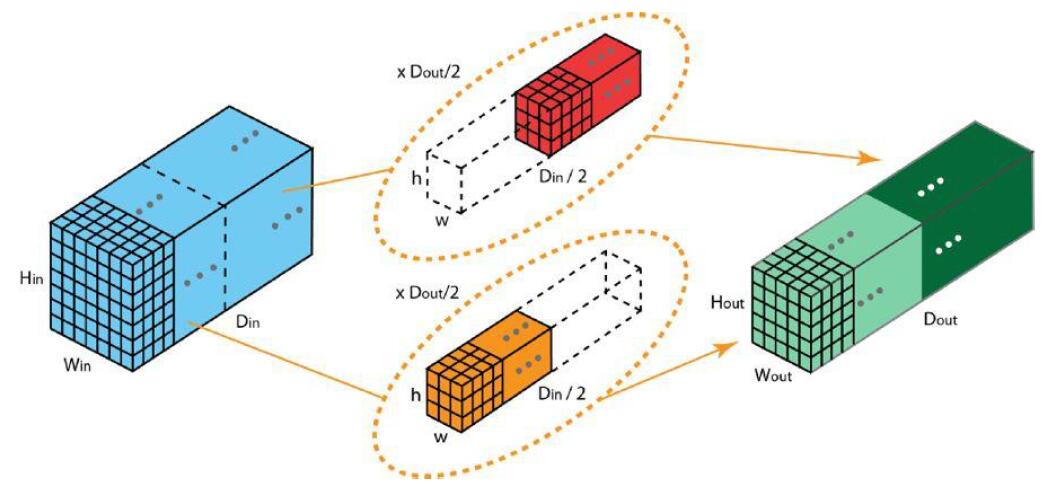
如果分成组,可以理解为把整个卷积考虑为个子问题,每个子问题是:
求解输入数据,经过卷积得到输出数据。
最后将得到的个输出数据拼接起来,得到输出。
在这个过程中,每一组卷积核大小为,卷积核的个数为,因此每组卷积的参数量为。由于一共有组,所以总参数量为。
可以看到,分为组的分组卷积参数量是常规卷积的。
深度卷积
深度卷积可视为特殊情况的分组卷积,此时有。
逐点卷积
逐点卷积就是的普通卷积,此时参数量化简为。
深度可分离卷积
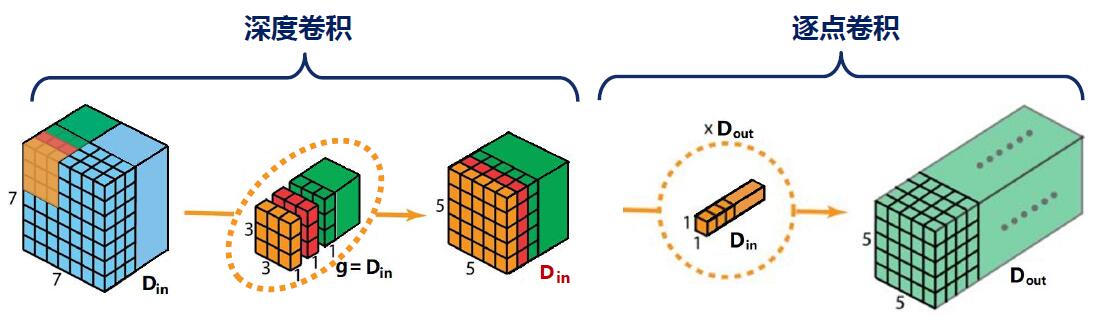
深度可分离卷积是深度卷积和逐点卷积的组合,首先对输入数据进行深度卷积,,参数量为;然后对中间输出数据进行逐点卷积使得通道数变为,这一步的参数量为。
深度可分离卷积的总参数量为。
基于Ghost特征的轻量化网络
Ghost模块使用较少卷积核对输入进行常规卷积,获得通道较少的输出特征并将其作为固有特征图;然后对固有特征图的每个通道进行线性变换,得到其对应的Ghost特征图;最后拼接在一起。
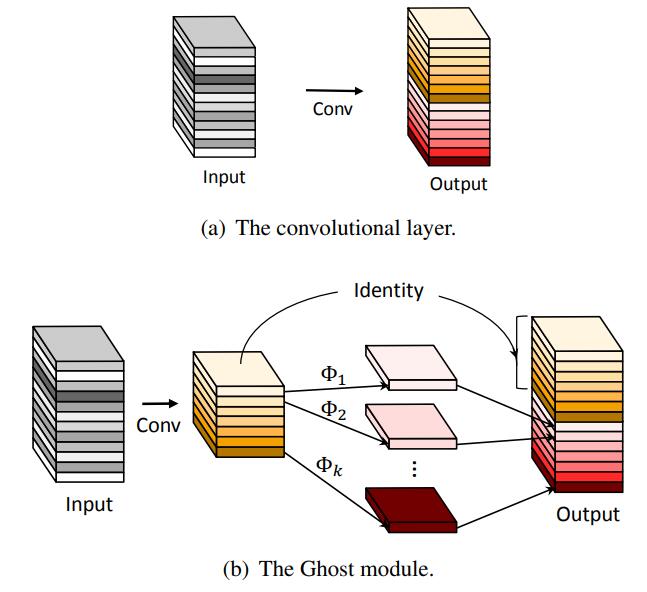
Ghost模块的特点:
具有很强的即插即用性
运算速度优化效果较明显
不能有效降低参数量及存储空间
知识蒸馏
大型的网络泛化能力较强,但不便于部署;知识蒸馏希望获得泛化能力强的小网络。首先训练一个泛化能力强的大网络(教师网络),然后结合训练数据和教师网络的“软预测”,再训练小网络(学生网络)。
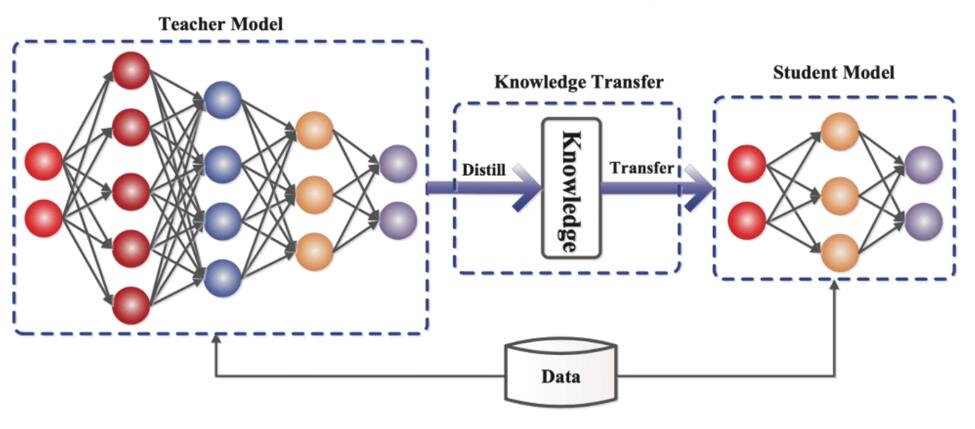
知识蒸馏的核心思想是:教师网络“软预测”的值携带了训练数据以外的泛化信息。“软预测”是指教师网络经过Softmax后的输出。小网络的目标函数就是:
前者对应了泛化能力,后者对应了训练数据的拟合程度。
使用Softmax的输出存在一个问题,Softmax的指数计算会放大差异,导致小值太小,训练效果不好;此时需要引入蒸馏温度,将Softmax函数变为:
此时可以通过调整的值,使得Softmax的输出更为平缓(有区分度且小值不至于太小)。