本页目录
行为识别R(2+1)D网络
论文A Closer Look at Spatiotemporal Convolutions for Action Recognition讨论了几种用于行为识别的时空卷积网络。文中提出了R(2+1)D网络,即将R3D网络中的3D卷积拆分成2D空间卷积+1D时间卷积。
PyTorch版本复现代码来自于Github仓库 Github: R2Plus1D-PyTorch
(2+1)D卷积
普通3D卷积的核大小为,为输入通道数、是3D卷积核的尺寸。
R(2+1)D网络最核心的改动就是将普通的Conv3d替换为SpatioTemporalConv卷积。
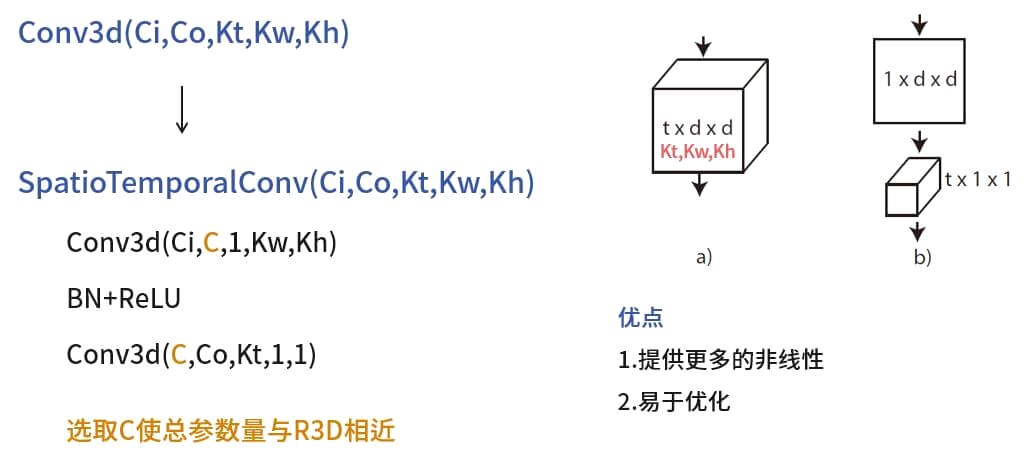
SpatioTemporalConv卷积从外部看与Conv3d相同,均有5个超参数,区别在于其内部的结构:
大小为的Conv3d
BatchNorm+ReLU
大小为的Conv3d
如果二者作用于相同的输出,得到的结果shape是一样的:
Python
import torch
from r2plus1d.module import SpatioTemporalConv
video_3d=torch.rand(8,3,60,32,32) #(batch*channels*frames*w*h)
conv3d=torch.nn.Conv3d(in_channels=3,out_channels=16,kernel_size=[7,5,5])
spconv=SpatioTemporalConv(in_channels=3,out_channels=16,kernel_size=[7,5,5])
output1=conv3d(video_3d)
output2=spconv(video_3d)
print(output1.shape) #torch.Size([8, 16, 54, 28, 28])
print(output2.shape) #torch.Size([8, 16, 54, 28, 28])
注意到拆分成两次卷积后,会出现一个中间通道数。论文中给出估计值的公式是:
这样做的目的是使得R(2+1)D卷积的参数量和R3D相近。也就是说,拆分时间和空间两次卷积并不是为了减少计算量。文中给出了使用R(2+1)D卷积两个优点:
1.
增加了网络非线性层的层数
2.
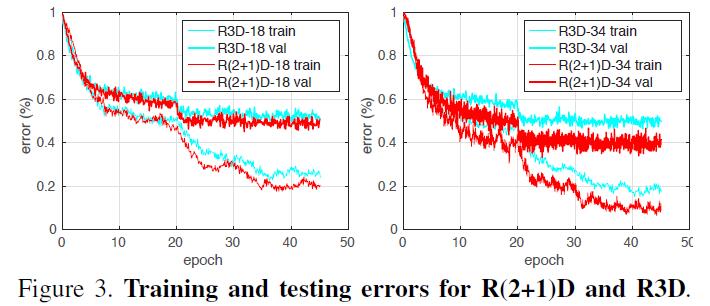
优化更容易(实验结果:R(2+1)D网络的训练和测试误差都更小)