本页目录
目标检测评价指标mAP
全类平均精度(mean Average Precision, mAP)用于评估目标检测模型性能。
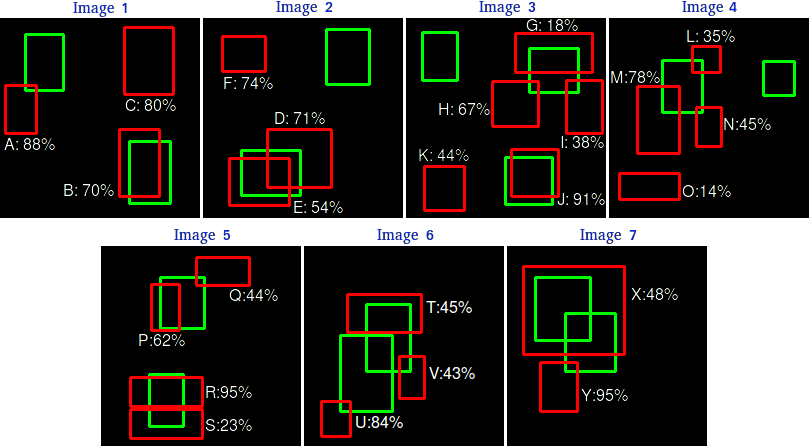
接下来围绕下面的例子逐步介绍mAP的计算。在下面的7张图片中共有15个目标,用绿色框标出;并且有24个检测框,用红色框标出,百分比数值表示置信度。
交并比
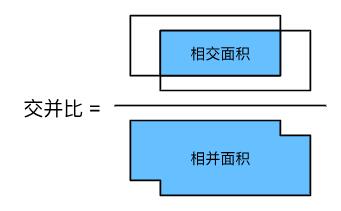
交并比(Intersection over Union, IoU)是产生的检测框与真实检测框的交集与并集的比值。
查准率和查全率
对于一组图像的目标检测结果来说,假如规定IoU大于某一阈值就把检测结果视为真正例TP,否则视为假正例FP;并且如果出现多个检测重叠一个真值的情况,只有最高置信度的检测框被视为TP,其他则视为FP。
接下来计算两个指标:查准率或精确率Precision,即预测为正的样本中的正确率TP/All Detections;查全率或召回率Recall,即正确检测出的正样本占所有正样本的比例TP/All Ground Truths。
对于上面的例子,按照置信度由高到低做出如下表格:
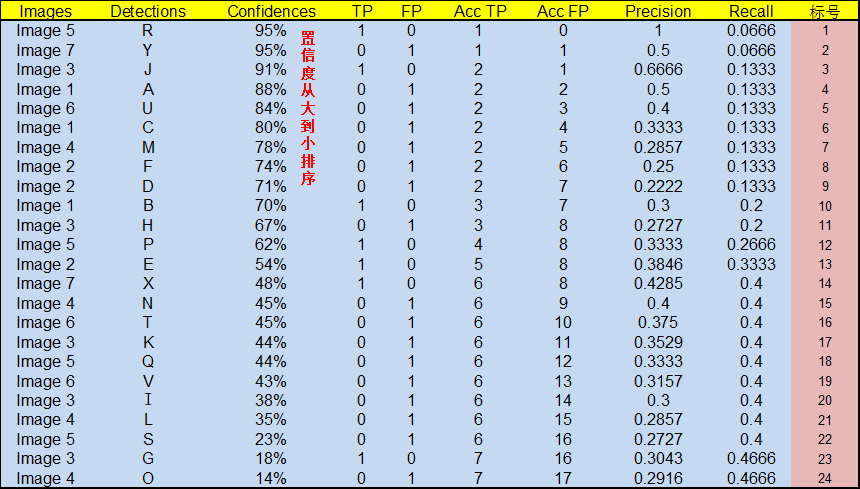
表格的前三列分别是图片编号、检测框编号和置信度;TPFP列标识出这个检测框是否为一个真正例;Acc TPAcc FP列是截至此行累计的TP和FP个数,用于Precision和Recall的计算;Precision列由Acc TP/(Acc TP + Acc FP)得到;Recall列由Acc TP/15得到(共有15个目标,因此All Ground Truths=15)。
平均精度AP
平均精度(Average Precision, AP)由近似计算Precision-Recall曲线下面积得出。
通常的计算方法是取曲线11点插值,不过无论如何计算,最后的含义都是希望得到近似的曲线下面积。因此在这里不展开介绍计算过程,而是讨论“曲线下面积”是如何与“平均精度”建立起联系的。
个人理解
当我们说模型在一个类别上预测精度是80%时,直观上的体会是“模型的10个预测框中,大约有8个是对目标的正确预测”。然而这并不能与Precision-Recall曲线下的面积建立起直观的联系。但注意到曲线的纵坐标的含义就是精度,从这个角度出发,以下是对AP指标的个人理解:
下面是一个常见的Precision-Recall曲线示意图。尽管现实任务中的曲线通常是不平滑、不单调的,但大致可以用图中的较为理想的曲线走势描述。我们通常用平衡点去衡量一个模型的好坏,也就是曲线上Precision=Recall的点。
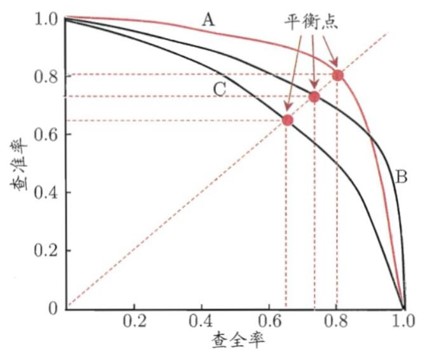
模型在平衡点处的精度与曲线下面积有没有联系呢?下图的蓝色折线D将曲线A的平衡点两侧的两段单调递减的曲线近似为直线,如果以折线D下面积近似曲线A下面积,将黄色三角形补到右侧后,可以发现蓝色折线D下的面积恰好反映了平衡点处的精度。
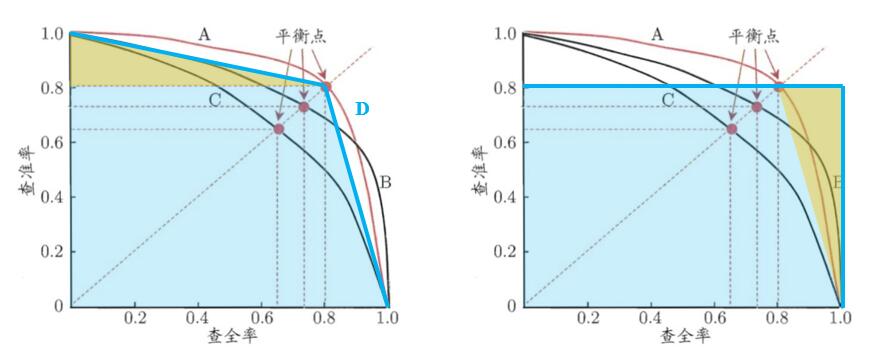
因此可以认为,平均精度AP某种意义上是用Precision-Recall曲线下面积近似反映了平衡点处的Precision值。
全类平均精度mAP
上述步骤算出的是针对一个类别的平均精度AP,而全类平均精度mAP是所有检测到的类别的AP均值。
为什么要分类计算AP,再取均值?
评估模型在目标检测任务上的性能时,通常用所有类别的AP的平均值,而不是将所有类别的检测结果混在一起,直接计算出一个数值,其中一个原因是:
当类别数量不平衡时,可能某个少样本类别的检测效果很差。如果混在一起计算,由于该类别样本数量较少,因此并不会对最终的结果产生很大的影响。此时对模型的性能评估是不准确的。因此需要逐类测量AP再取均值,作为最终的mAP检测结果。
参考资料
本文的部分内容、图片来源于: