本页目录
学习RNN和LSTM
RNN:一个简单的例子
传统神经网络每次的输入是独立的,每次输出只依赖于当前的输入;但在某些任务中需要更好的处理序列信息,即前面的输入和后面的输入是有关系的;循环神经网络(Recurrent Neural Networks, RNN)通过使用带自反馈的神经元,能够处理任意长度的序列。
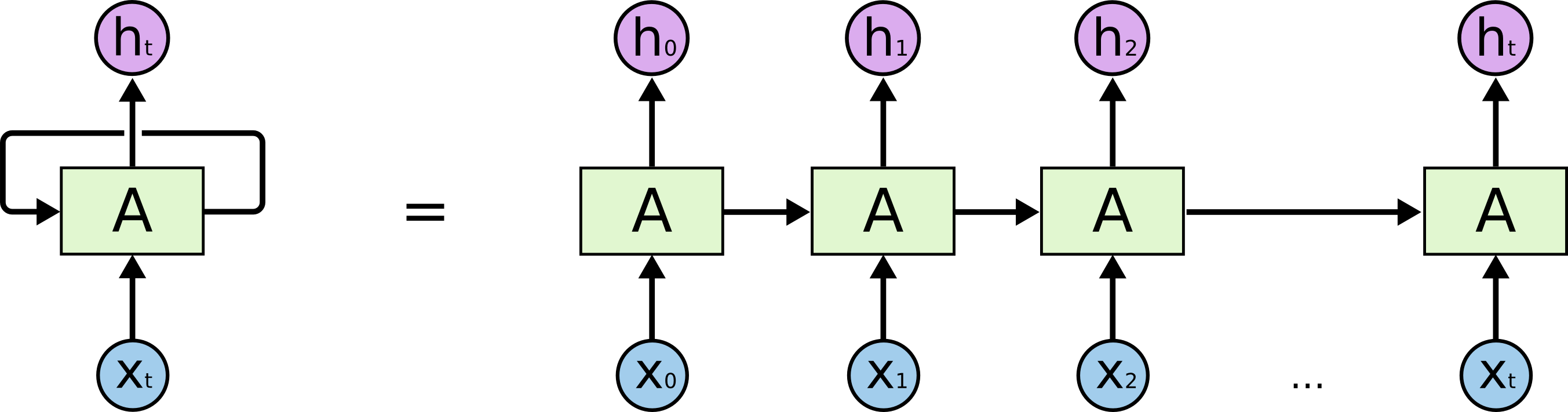
下面是一个非常常见的RNN结构描述图。它展示了RNN的自反馈机制和与时间的依赖关系,但是对网络结构的描述容易引起误解:右侧的展开形式并不意味着网络有t层,而是反映了随着时间增加(有时也可以理解为随着程序中循环的迭代),上一次输出的隐藏状态,和共同作为网络的下一次的输入。
或者,如果说CNN是从空间维度上堆叠卷积层,不断加深,RNN就是从时间维度上的延展,而其网络真正的参数是很少的。
下面以一个简单的正弦序列预测任务出发,结合代码理解RNN网络的部分细节。
预测一个正弦序列
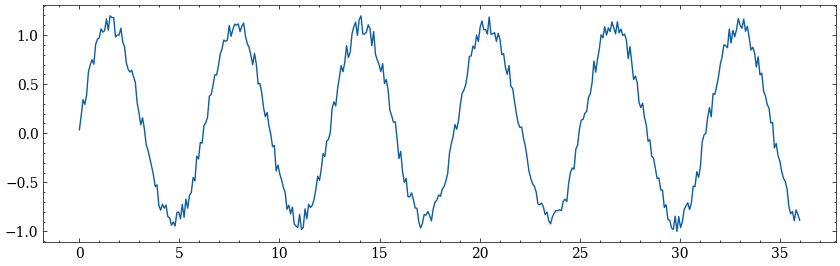
这个例子中,我们对一个加了噪声的正弦序列进行预测。
import numpy
import torch
from torch import nn
import matplotlib.pyplot as plt
#生成加噪声的正弦序列数据
xlim=numpy.linspace(0,36,400)
y=numpy.sin(xlim)+numpy.random.rand(*xlim.shape)*0.2
#转换dtype和size,保持和后面的训练数据统一
y=y.reshape(-1,1).astype("float32")
plt.plot(xlim,y)
plt.show()
代码中我们在区间取了400点数据,如果把横轴看成时间轴,可以认为数据集中有400个连续时间点的数据。
现在明确一下我们的方案:
使用前80%也就是前320个数据作为训练集,剩余的作为测试集,观察预测结果。
序列长度为10,也就是模型根据前10个时间点的数据去预测下一个时间点的数据。
这个例子中输入特征的维度是1,也就是只有y值一个指标。此外,也不考虑批量大小。
定义RNN网络
class MyRNN(nn.Module):
def __init__(self,input_size,hidden_size,output_size):
super().__init__()
self.linear_ih=nn.Linear(input_size,hidden_size)
self.linear_hh=nn.Linear(hidden_size,hidden_size)
self.linear_ho=nn.Linear(hidden_size,output_size)
self.tanh=nn.Tanh()
def forward(self,x,prev_state):
curr_state=self.tanh(
self.linear_ih(x)+self.linear_hh(prev_state)
)
output=self.linear_ho(curr_state).reshape(1)
return output,curr_state
hidden_size=12
my_rnn=MyRNN(input_size=1,hidden_size=hidden_size,output_size=1)
loss_func=nn.MSELoss()
optimizer=torch.optim.SGD(my_rnn.parameters(),lr=0.01)
这个是一个简单的RNN结构,从网络参数和结构来看很像一个输入层-隐藏层-输出层的感知机,但是多了一步隐藏层-隐藏层的连接,RNN的反馈结构就是由此体现的。
并且,注意到forward函数的输入也需要两个参数:当前时刻输入x和前一时刻状态prev_state,同时也会把计算后的新状态curr_state和output一起返回,供下一次计算使用。在这里,经过linear_ho后,output的size为(1,1),考虑到它仅仅是一个标量,我们把它resize为(1)。
接下来设置了一些超参数,隐藏层有12个神经元,损失函数使用MSELoss()。
训练
首先定义这样的训练函数:它传入一个序列train_seq和目标target。train_seq的size应该为(10,1),因为我们用前10个时间点的数据去预测下一个,而输入特征维度是1;target的size应该为(1),因为输出只是一个标量。注意我们循环依次输入train_seq中的10个数据,迭代更新state,用最后一次的output作为最终的输出计算损失。
def train(train_seq,target):
#初始状态
state=torch.zeros(1,hidden_size)
for x in train_seq:
output,state=my_rnn(x,state)
loss=loss_func(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#返回损失
return loss.detach().numpy().reshape(1)
下面代码把真实数据划分成:
|
|
|---|---|
|
|
|
|
|
|
... | ... |
|
|
train_datas=[]
for i in range(320-10):
train_seq=torch.from_numpy(y[i:i+10])
target=torch.from_numpy(y[i+10])
train_datas.append((train_seq,target))
训练网络,绘制误差:
metrics=[]
my_rnn.train()
for train_seq,target in train_datas:
loss=train(train_seq,target)
metrics.append(loss)
plt.subplot(211)
plt.plot(metrics,label="loss")
plt.legend()
预测
这个例子中我们用单步预测观察模型的效果。在单步预测时,每次预测都全部使用真实值;当然,我们可以这样做是因为验证集中本来就包含了真实的数据,换句话说,我们是在已知t+1时刻的真实数据的情况下,去看看模型使用t-9~t时刻的数据,对t+1时刻的预测值。
|
|
|---|---|
|
|
|
|
|
|
... | ... |
def pred(truth_seq):
with torch.no_grad():
state=torch.zeros(1,hidden_size)
for x in truth_seq:
output,state=my_rnn(x,state)
return output
preds=[]
for i in range(320-10,400-10):
truth_seq=torch.from_numpy(y[i:i+10])
preds.append(pred(truth_seq).numpy())
preds=numpy.array(preds).reshape(-1,1)
plt.subplot(212)
plt.plot(xlim,y,label="truth")
plt.plot(xlim[320:400],preds,"red",label="predict")
plt.legend()
plt.show()
如果我们不只是在测试集上评估模型性能,而是去预测真实生活中的问题,例如未来7天的温度;或者假如我们的数据集到y[319]就截止了,这时如果想得到后面多个时刻的数据,就需要多步预测,此时上一时刻的预测会被当做新的输入:
|
|
|---|---|
|
|
|
|
|
|
... | ... |
多步预测会导致误差的累积。
看看效果
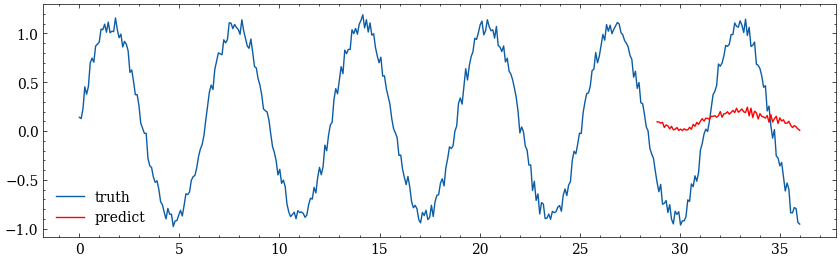
如果不执行训练步骤的代码,使用初始随机参数的模型预测结果是:
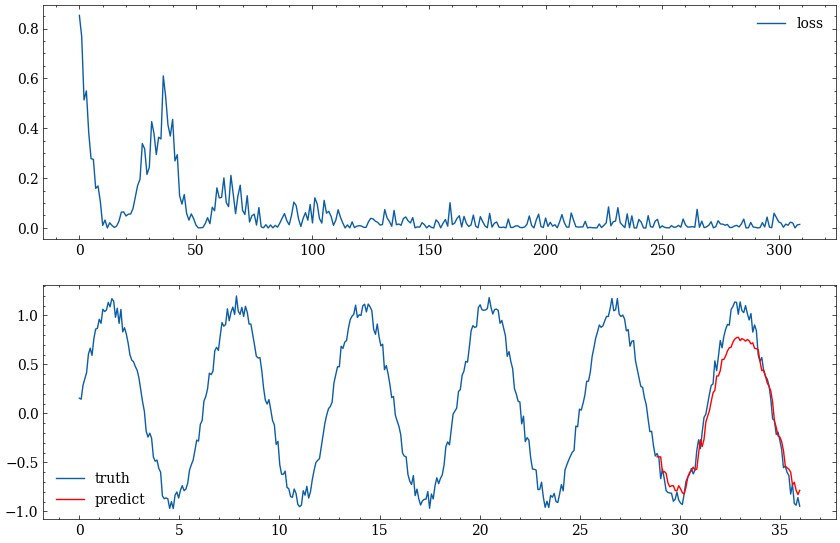
经过训练后,每次训练的loss和最终的预测:
使用torch.nn.RNN
使用torch.nn.RNN模块时,与上面例子中手动实现的RNN有几处细小的区别,下面给出了使用torch.nn.RNN时需要做出的修改:
定义模型时,不再需要显式指定linear_ih和linear_hh两层,将由nn.RNN模块实现;nn.RNN模块没有定义输出层,因此输出层linear_ho需要设置。
在forward函数中,手动实现时为了直观展示出RNN的迭代过程,只进行了一次隐藏状态的更新;而对于输入序列迭代更新隐藏状态是在训练和预测时实现的。而nn.RNN模块的一次forward就已经完成了迭代更新,其输入是整个序列seq和prev_state,返回值是output_hidden,curr_state,对于不考虑批量大小的数据,它们的size为:
seq: (sequence_length, input_size)
init_state: (1, hidden_size)
output_hidden: (sequence_length, hidden_size)
state: (1, hidden_size)
最后在我们定义的MyRNN模块中,用output_hidden的最后一个时间点的输出,经过输出层得到最终的output。
手动实现
class MyRNN(nn.Module):
def __init__(self,input_size,hidden_size,output_size):
super().__init__()
self.linear_ih=nn.Linear(input_size,hidden_size)
self.linear_hh=nn.Linear(hidden_size,hidden_size)
self.linear_ho=nn.Linear(hidden_size,output_size)
self.tanh=nn.Tanh()
def forward(self,x,prev_state):
curr_state=self.tanh(
self.linear_ih(x)+self.linear_hh(prev_state)
)
output=self.linear_ho(curr_state).reshape(1)
return output,curr_state
使用torch.nn.RNN
class MyRNN(nn.Module):
def __init__(self,input_size,hidden_size,output_size):
super().__init__()
self.rnn=nn.RNN(input_size=input_size,hidden_size=hidden_size,batch_first=True)
self.linear_ho=nn.Linear(hidden_size,output_size)
def forward(self,seq,init_state):
output_hidden,tate=self.rnn(seq,init_state)
output=self.linear_ho(output_hidden[-1,:]) #取最后一个时间点的输出
return output,state
训练和预测时,也不需要再遍历序列,迭代的过程已经在nn.RNN模块内部实现。
手动实现
def train(train_seq,target):
state=torch.zeros(1,hidden_size)
for x in train_seq:
output,state=my_rnn(x,state)
loss=loss_func(output,target)
# ......
def pred(truth_seq,net):
with torch.no_grad():
state=torch.zeros(1,hidden_size)
for x in truth_seq:
output,state=net(x,state)
return output
使用torch.nn.RNN
def train(train_seq,target):
state=torch.zeros(1,hidden_size)
output,_=my_rnn(train_seq,state) #一次得到输出
loss=loss_func(output,target)
# ......
def pred(truth_seq):
with torch.no_grad():
state=torch.zeros(1,hidden_size)
output,_=my_rnn(truth_seq,state) #一次得到输出
return output
FAQ
初次了解RNN时,我在一些问题上困惑了很久。这个版块是对它们的再次整理。(尽管有些已经包含在上述例子中了!)
用10步预测下1步,为什么 input_size 不是10,而是1?
input_size与序列长度并非同一个概念。用前10个时间点的数据去预测下一个,这里的10是序列长度;而input_size是输入特征的维度。由于这个例子较为简单,只是用历史的y值预测新的y值,因此特征只有1维。
什么时候 input_size 不是1?
例如我们在预测未来气温时,历史气温数据并不是唯一的参考,还可能参考历史的风速、气压、天气情况等等,此时输入数据将会是一个input_size维的向量。
hidden_size=12,12是在哪里体现的?
12只是模型的超参数,和MLP中隐藏层大小一样,并没有太多的物理含义。
训练时,每次迭代用哪些数据?应该遍历几遍数据集?每个 epoch 会使用哪些数据进行参数优化?
在训练一个CNN网络时(例如一个图片分类网络),策略通常是:
指定超参数num_epoch,在每个epoch中随机遍历训练集中的所有图像进行参数优化;
重复执行num_epoch次。
然而对于RNN来说这个概念似乎并不清晰,例如上述例子的训练策略是:
从0到(训练集大小 - 序列长度)依次遍历起始时间t;
对于每个起始时间t,将y[t]~y[t+9]为输入,y[t+10]为真值作为一组训练样本。
第1步只遍历了一次!
或者:
...
...
前两步同上,但多次遍历训练集。
另一个常用的策略是:
指定超参数:训练轮次num_iter;
重复执行num_iter次,每次随机抽取一个起始时间t,并且将y[t]~y[t+9]为输入,y[t+10]为真值作为一组训练样本。
LSTM:一篇很好的博客
以下的内容和插图总结或翻译自这篇的英文博客:Understanding LSTM Networks
长期依赖问题
RNN可以利用先前的信息理解当前的任务,这点非常不错;有时我们只需要短期的信息,例如一个语言模型预测下面的句子:天空中飘着一朵白色的【云】,这很简单。但有些时候我们需要更多背景信息,例如:我出生在法国,…… ,我可以说流利的【法语】,这个情况下,随着前后文距离变大,RNN对长期依赖关系的学习会变得困难。
LSTM
长短期记忆网络(Long Short-Term Memory, LSTM)是一种特殊的RNN,可以学习长期依赖。以RNN为例,循环神经网络随时间展开通常具有如下的示意图:
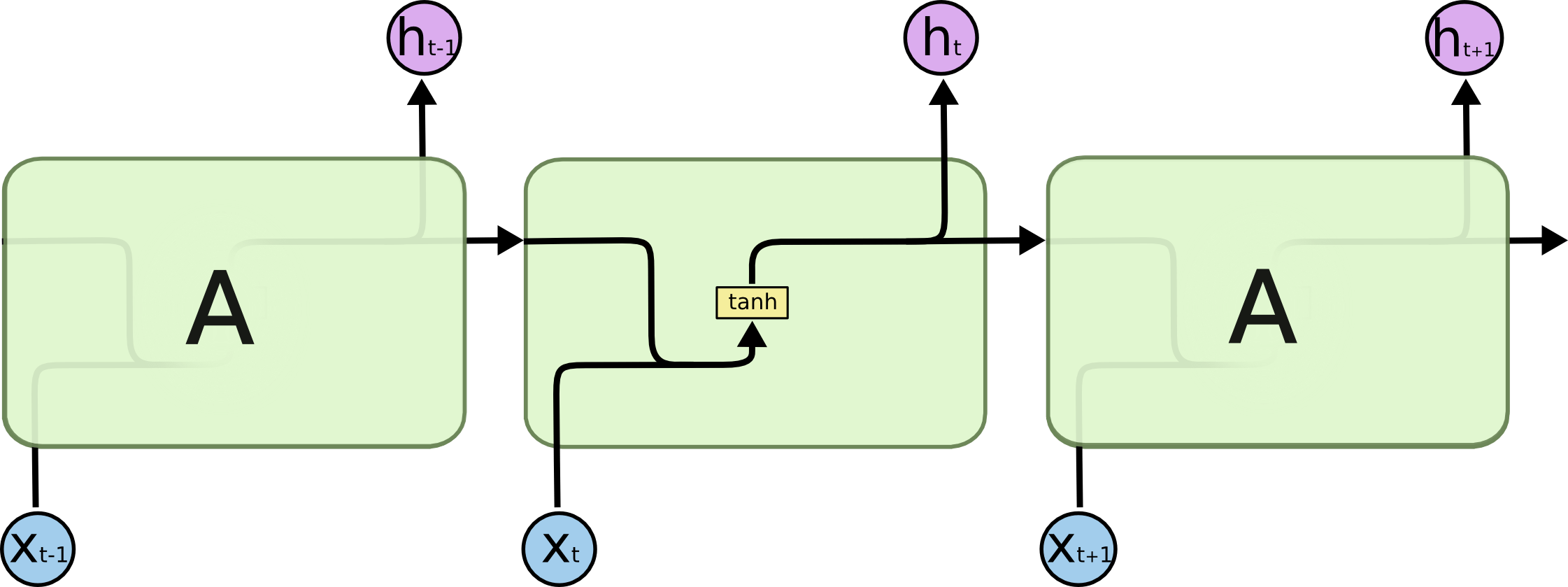
对于RNN来说,利用历史状态和输入得到新的状态,只经过一个简单的tanh激活层,而对于LSTM来说,它的示意图略显复杂:
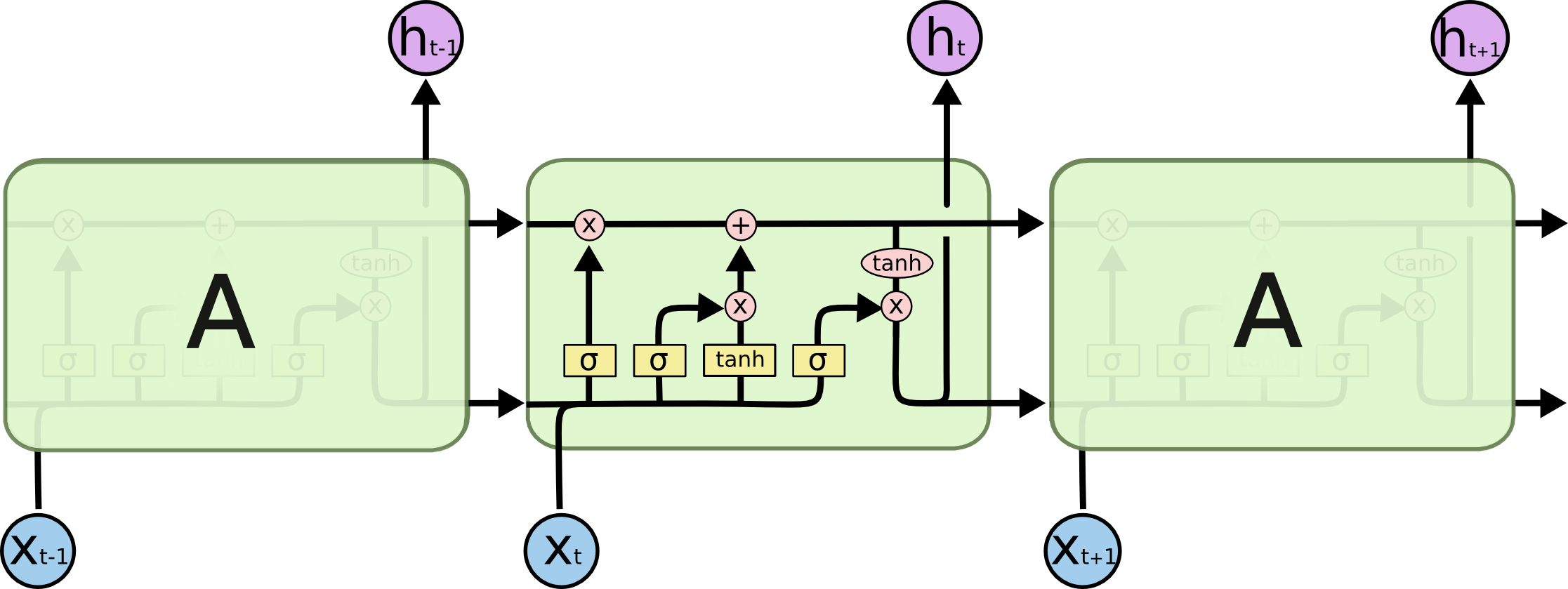
在上图中,每条线表示一个向量,粉红色圆圈表示逐点式操作,黄色的方框是神经网络的层。这看起来很眼晕,不过我们接下来会一点点的解释图里的内容。
门控单元
下面的结构称为门控单元:
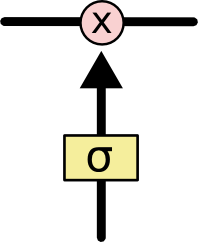
门控单元控制信息量通过的多少,通过向量来控制通过的信息量:
式子中表示按位置相乘,的每个元素输出范围是,某个元素接近1,对应位置保留的信息就越多,反之就越少。
逐部分分析LSTM
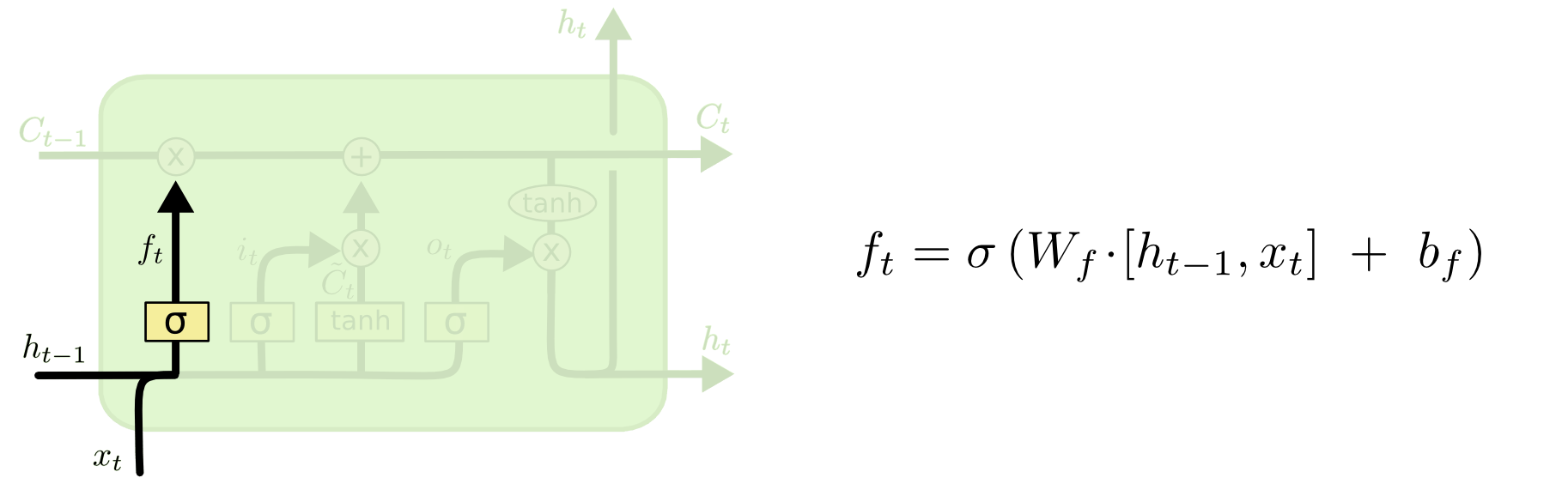
遗忘门
LSTM的第一步是决定什么应该被遗忘,也就是对上一个单元(cell)状态信息选择性的遗忘。
这个操作由遗忘门实现,将其范围的输出按位置与单元上一时刻状态相乘。
举一个概念性的例子:
考虑一个语言模型,输入一个句子:Alice是一名女教师,她喜欢给学生讲课;Bob是一位男司机,他喝酒上瘾。
当模型看到Alice是一名女教师,……时,单元状态中可能存储了和主语Alice和女教师有关的语义信息,以便在后文输出合适的代词她;然后,当模型看到Alice是一名女教师,她喜欢给学生讲课;Bob是一位男司机,……时,我们希望在看到新主语Bob和男司机之后,忘记此前存储的旧主语的性别语义。也就是对旧单元状态乘上较小的。
输入门
下一步就是决定要在单元中存入什么新的信息。这一部分有两路:tanh这一路与普通RNN很像,生成一个中间状态;这一路被称为输入门,控制这个中间状态有多少信息被存入单元。
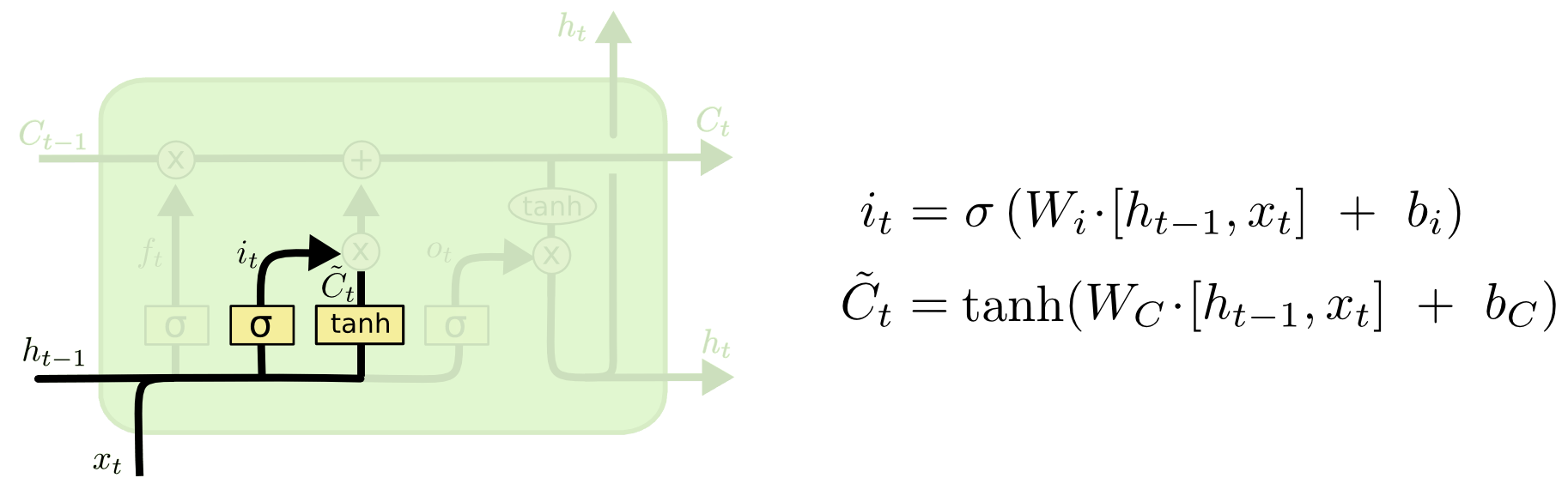
经历这两步之后,便可以相加得到新的单元状态:
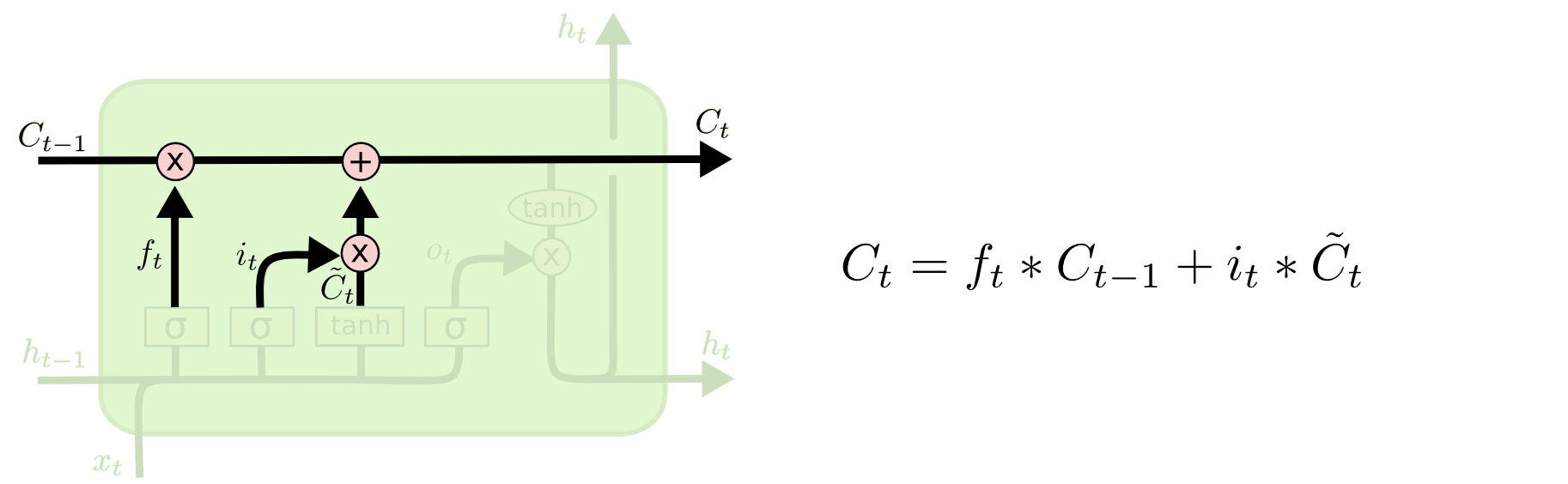
同理,当模型看到Bob是一位男司机时,我们可能会想丢掉此前的语义信息女性,并把新的语义信息男性存入单元状态,使得后文输出正确的代词他。
输出门
最后是决定新的隐藏状态,这个输出会基于单元状态,但会经过门控单元。输出门决定经过tanh的单元状态有多少被输出到下一时刻的隐藏状态。
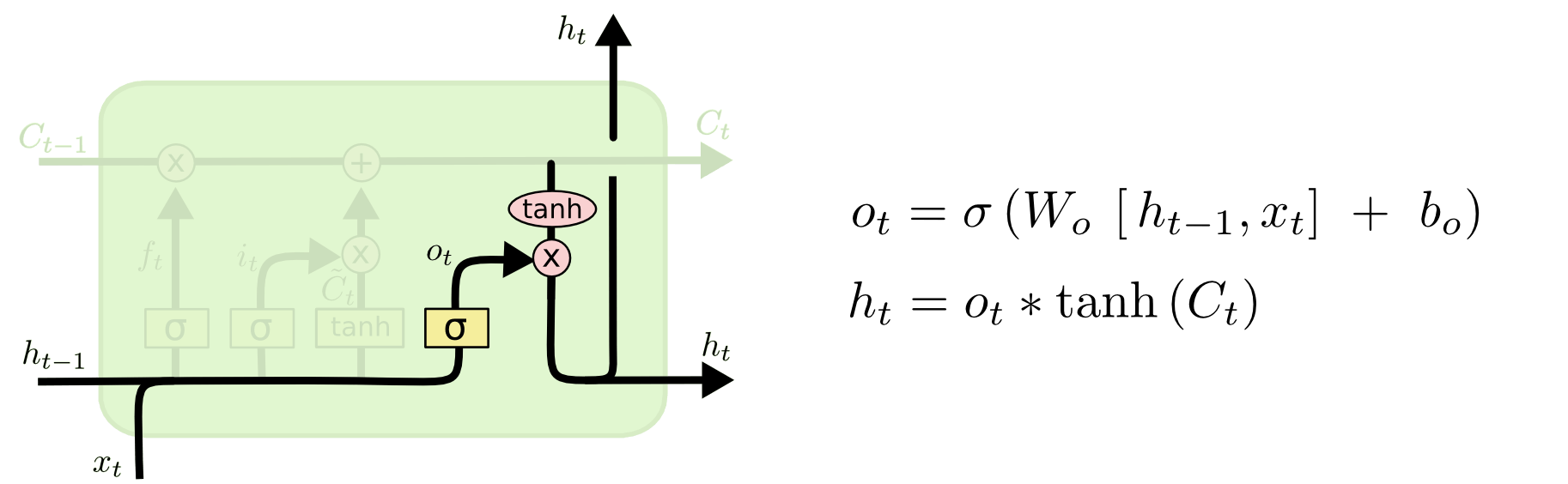
当看到Bob是一位男司机,他……时,由于出现了主语他,模型可能会输出和谓语动词有关的语义信息。