本页目录
【模式识别】参数估计
上一篇提到的统计决策方法,类条件密度按已知处理。但实际问题中,往往只有已知样本,需要根据已知样本推测分布。
本章讨论的是参数估计,也就是分布的表达式形式是已知的,只是希望确定其中参数的值。
最大似然估计
假设样本的分布形式已知,现在想确定参数。如果已经观测到了一些样本,记这些样本为,则我们要找的参数即为:使得出现观测样本概率最大的参数。
考虑下面的例题:
每一个样本都形如,其中的每个维度都是二值变量,其分布可以由描述,即的概率为,相应地,的概率为。假设现在已经观察到样本,希望估计参数。
注意,如果样本有多个维度,这里记为,、表示样本的分量;
有时,若样本只有一个维度,则样本会直接简记为;此时、表示两个样本。
请注意语义。
观测到样本的概率为:
式子中的代表第个样本的第个分量,其值为0或1。
取对数似然函数:
求偏导得:
得,即
把每一个分量都叠加起来,就得到最终的参数估计:
举一个带有具体数值的例子,假如观测到了四个样本:、、、,则估计参数
其含义为,对于第一个维度,四个样本均为1,因此估计的概率为1;对于第二个样本,四个样本中有两个为1,另外两个为0,则估计的概率为0.5,以此类推。
正态分布下的最大似然估计
单变量正态分布
多变量正态分布
贝叶斯估计
贝叶斯估计与最大似然估计一个根本的区别是,最大似然估计把未知参数当作固定的量,而贝叶斯估计把未知参数本身也看作随机变量。假设未知参数是,其分布空间为,定义损失函数表示估计误差的损失。如果已经观测到了样本集,那么我们的目标是:
最小化期望风险:
通常情况下损失函数取,此时有结论:
在给定样本集下,的贝叶斯估计量是。
在平方损失函数下,贝叶斯估计的步骤是:
猜测参数的先验分布
对于参数估计问题,样本的概率密度函数形式已知为,形式上求出样本集分布为:
利用贝叶斯公式求的后验概率分布:
的贝叶斯估计量是
重新理解
重述上面四个步骤,以免迷失在众多符号之中。
假设我们拿到了正态分布下的样本集,其中,,,已知正态分布的方差,现在只需要估计均值。
样本集中的每个样本出现的概率是可以由正态分布写出的,把所有样本的出现概率相乘,就得到了当前样本集出现的概率为,这也就是上述步骤2提到的样本集分布。
是一个只含的表达式。我们记
如果采用极大似然估计,那么做到这里对或求导,使得导数为0的点就是估计值;取可以使得观测到样本集的概率最大。
概率论的两个学派中,频率学派认为应从客观掌握的数据来计算概率;而贝叶斯学派则认为概率是有先验和后验的,我们要计算的是后验概率,这个后验概率又是以先验概率为基础的。如果采用贝叶斯估计,会假设参数存在先验分布(步骤1),这里假设服从均匀分布:
步骤3中,公式可以重写为:
首先来看分母,其含义是综合考虑所有可能的取值,求出一个“平均的”样本集出现概率。这个积分式可以求出具体数值,而不是含的式子。从数学的角度可以理解为,使等号左侧后验概率密度积分为1的归一化常数。
再看其他的三个量,、、,这是贝叶斯学派的经典思想:用样本修正先验概率,得到后验概率。这三个式子都可以写为仅含的函数。当然,因为假设的先验分布简单(均匀分布),为常数。
这三个式子虽然都是的函数,但描述的含义有所区别。、描述的是的分布概率,而描述的是样本集的出现概率。
与最大似然估计一样,贝叶斯估计也会给出参数具体的估计值。但到此步,我们只给出了的后验分布。要给出估计值,首先要明确我们的目标是什么:
最大似然估计的目标是,带入估计值可以使得样本集出现概率最大;
而贝叶斯估计的目标是,带入估计值可以使得期望风险(定义见上文)最小。
进一步地,在损失函数为平方误差时,有结论可以给出估计值的具体数值,也就是步骤4。
贝叶斯学习
现在我们逐一考虑每一个样本。没有样本的时候,要估计的参数先验分布为。
观测到第一个样本的时候,用其来修正先验分布,也就是:
现在继续观测到第二个样本,此时根据贝叶斯学派用数据修正先验的思想,先验分布是上一轮得到的,修正后的后验分布为
以此递推:
贝叶斯学习程序实现
假设我们有一个方差的正态分布样本集,均值待估计。
import matplotlib.pyplot as plt
import numpy
import math
#生成样本集,样本集的真实均值为m=13
Xs=numpy.random.normal(13,3,100)
#计算某个样本X出现的概率
def P(X,m,s=3):
return numpy.exp(-(X-m)**2/(2*s*s))/(s*numpy.sqrt(2*math.pi))
#假设mX的先验分布也是一个正态分布,初始的均值m0=4、方差s0=4
m0=4
s0=4
#mX的分布区间,理论上应该是(-inf,inf),但由于两侧足够趋近于0,这里取(-40,40)
m_lim=numpy.arange(-40,40,0.01)
#无样本时m的先验分布
pm=P(m_lim,m0,s0)
#数值积分
def numint(f):
s=0
step=m_lim[1]-m_lim[0]
for i in range(len(m_lim)-1):
s+=step*f[i]
return s
#逐个样本学习
for i,X in enumerate(Xs):
if (i+1)%20==0 or i<5:
plt.plot(m_lim,pm,label=f"epoch {i+1}")
#样本出现概率,在参数m分布区间上对应的值
pX_m=P(X,m_lim)
#用pX_m(数据)修正pm(先验),得到pm_X(后验)
pm_X = pX_m*pm / numint(pX_m*pm)
#把第i轮得到的后验分布,视作第i+1轮迭代的先验分布
pm=pm_X
plt.legend()
plt.show()
观察迭代结果:
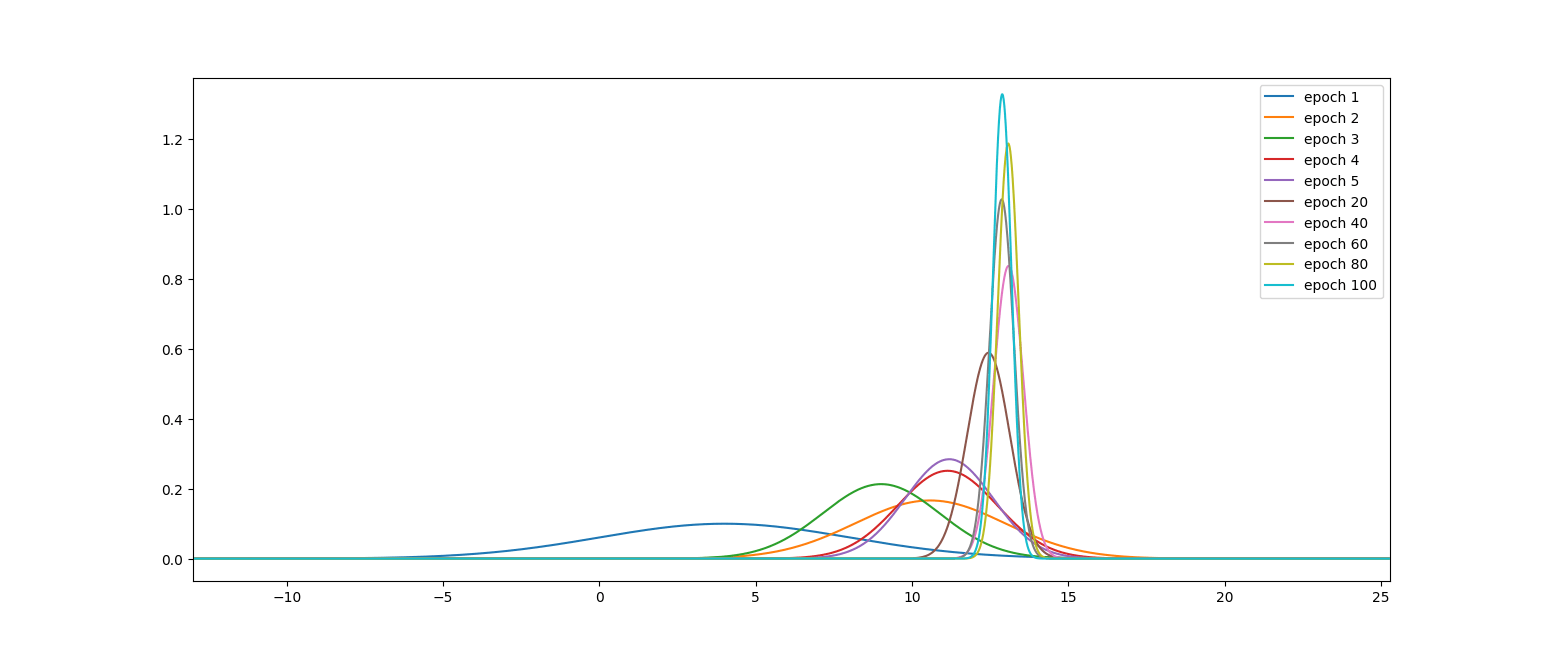
如果随着样本数增加,后验概率序列逐渐尖锐,最终趋向于以参数真实值为中心的一个尖峰,则这一过程称为贝叶斯学习。
正态分布下的贝叶斯估计
假设要估计的正态分布均值未知,方差已知。假定的先验分布也是正态分布,均值为,方差为。
假设观测到的个样本的均值为,这里直接给出结论:
可以看到贝叶斯估计结果由两部分构成,第一项是样本知识,第二项是先验知识。
样本数量为0时,估计值完全等于先验;样本数量为无穷时,估计值趋于样本均值;
若,则先验知识绝对可靠,样本不起作用;
若,则先验知识十分不确定,估计值近似等于样本均值。
贝叶斯估计的优势在于,可以结合样本信息和先验知识,并且根据样本数量和先验知识的确定程度调和两部分信息的相对贡献。